Flask app 2 - word counts via BeautifulSoup, and Natural Language Toolkit (NLTK) with Gunicorn/PM2/Apache

In this tutorial, we'll construct the back-end logic to scrape and then process the word counts from a webpage using BeautifulSoup, and Natural Language Toolkit (NLTK) libraries.
We calculate word-frequency pairs based on the text from a given URL.
New tools used in this tutorial:
- requests (2.9.1) - a library for sending HTTP requests
- BeautifulSoup (4.4.1) - a tool used for scraping and parsing documents from the web
- Natural Language Toolkit (3.2) - a natural language processing library
$ pip install requests==2.9.1 beautifulsoup4==4.4.1 nltk==3.2 $ pip freeze > requirements.txt
Github source : akadrone-flask
We need to set up the route to render a form to accept URLs.
First, we created a templates/index.html file which uses Bootstrap.
<!DOCTYPE html>
<html>
<head>
<title>Wordcount</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="//netdna.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css" rel="stylesheet" media="screen">
<style>
.container {
max-width: 1000px;
}
</style>
</head>
<body>
<div class="container">
<h1>Wordcount 3000</h1>
<form role="form" method='POST' action='/'>
<div class="form-group">
<input type="text" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;" autofocus required>
</div>
<button type="submit" class="btn btn-default">Submit</button>
</form>
<br>
{% for error in errors %}
<h4>{{ error }}</h4>
{% endfor %}
</div>
<script src="//code.jquery.com/jquery-2.2.1.min.js"></script>
<script src="//netdna.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script>
</body>
</html>
Then we added a form with a text input box for users to enter a URL. Additionally, we utilized a Jinja for loop to iterate through a list of errors, displaying each one.
Here is the updated aka.py to serve the template:
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config.from_object('config')
app_settings = app.config['APP_SETTINGS']
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://localhost/wordcount_dev'
db = SQLAlchemy(app)
from models import *
@app.route('/', methods=['GET', 'POST'])
def index():
return render_template('index.html')
if __name__ == '__main__':
app.run()
Note that we're using both of HTTP methods, methods=['GET', 'POST']. We will eventually use that same route for both GET and POST requests - to serve the index.html page and handle form submissions, respectively.
$ python manage.py runserver * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Or on local Apache:
In order to grab the HTML page from the submitted URL, we're going to import the requests library.
The code update looks like this:
import requests
from flask import Flask, render_template, request
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config.from_object('config')
app_settings = app.config['APP_SETTINGS']
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://localhost/wordcount_dev'
db = SQLAlchemy(app)
from models import *
@app.route('/', methods=['GET', 'POST'])
def index():
errors = []
results = {}
if request.method == "POST":
# get url that the user has entered
try:
url = request.form['url']
r = requests.get(url)
print(r.text)
except:
errors.append(
"Unable to get URL. Please make sure it's valid and try again."
)
return render_template('index.html', errors=errors, results=results)
if __name__ == '__main__':
app.run()
As we can see from the code above, we imported the requests library to send external HTTP GET requests to grab the specific user-provided URL. Also, request object from Flask is imported to handle GET and POST requests within the Flask app.
Then, we added variables to capture both errors and results, which are passed into the template.
$ python manage.py runserver
If we type in a valid webpage, we can see the text of that page returned.
Now we'll be able to count the frequency of the words of the page and display them to the end user. Here is the updated code aka.py:
import requests
import operator
import re
import nltk
from flask import Flask, render_template, request
from flask.ext.sqlalchemy import SQLAlchemy
from stop_words import stops
from collections import Counter
from bs4 import BeautifulSoup
app = Flask(__name__)
app.config.from_object('config')
app_settings = app.config['APP_SETTINGS']
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://localhost/wordcount_dev'
db = SQLAlchemy(app)
from models import *
@app.route('/', methods=['GET', 'POST'])
def index():
errors = []
results = {}
if request.method == "POST":
# get url that the person has entered
try:
url = request.form['url']
r = requests.get(url)
except:
errors.append(
"Unable to get URL. Please make sure it's valid and try again."
)
return render_template('index.html', errors=errors)
if r:
# text processing
raw = BeautifulSoup(r.text, 'html.parser').get_text()
nltk.data.path.append('./nltk_data/') # set the path
tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens)
# remove punctuation, count raw words
nonPunct = re.compile('.*[A-Za-z].*')
raw_words = [w for w in text if nonPunct.match(w)]
raw_word_count = Counter(raw_words)
# stop words
no_stop_words = [w for w in raw_words if w.lower() not in stops]
no_stop_words_count = Counter(no_stop_words)
# save the results
results = sorted(
no_stop_words_count.items(),
key=operator.itemgetter(1),
reverse=True
)
try:
result = Result(
url=url,
result_all=raw_word_count,
result_no_stop_words=no_stop_words_count
)
db.session.add(result)
db.session.commit()
except:
errors.append("Unable to add item to database.")
return render_template('index.html', errors=errors, results=results)
In our route we used beautifulsoup to remove the HTML tags from the text we got from the URL.
We're also using nltk to tokenize the raw text (break up the text into individual words), and turn the tokens into an nltk text object.
We may not want to count the words such as "I", "me", "the", and so forth. These are called stop words.
stop_words.py:
stops = [
'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you',
'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his',
'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself',
'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which',
'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are',
'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having',
'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if',
'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for',
'with', 'about', 'against', 'between', 'into', 'through', 'during',
'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in',
'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then',
'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any',
'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no',
'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's',
't', 'can', 'will', 'just', 'don', 'should', 'now', 'id', 'var',
'function', 'js', 'd', 'script', '\'script', 'fjs', 'document', 'r',
'b', 'g', 'e', '\'s', 'c', 'f', 'h', 'l', 'k'
]
In order for nltk to use properly, we need to download the correct tokenizers. So, let's create a new directory nltk_data:
$ mkdir nltk_data
Run:
$ python -m nltk.downloader -d nltk_data
NLTK Downloader
---------------------------------------------------------------------------
d) Download l) List u) Update c) Config h) Help q) Quit
---------------------------------------------------------------------------
Downloader> d
Download which package (l=list; x=cancel)?
Identifier> punkt
Downloading package punkt to nltk_data...
Unzipping tokenizers/punkt.zip.
---------------------------------------------------------------------------
d) Download l) List u) Update c) Config h) Help q) Quit
---------------------------------------------------------------------------
Downloader> q
Note that in the code we imported re and created a regular expression because we don't want punctuation counted in the final results.
Next, using a list comprehension, we created a list of words without punctuation or numbers. Then, we tallied the number of times each word appeared in the list using Counter.
In the code shown in previous section, with the stops list imported from the stop_words.py, we used a list comprehension to create a final list of words that do not include those stop words.
Next, we created a dictionary with the words and their associated counts (as keys and values). And then, we used the sorted() method to get a sorted representation of our dictionary.
Now we can use the sorted data to display the words with the highest count at the top of the list, which enables us not to use that sorting in our Jinja template.We need to update index.html in order to display the results.
index.html:
<!DOCTYPE html>
<html>
<head>
<title>Wordcount</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="//netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css" rel="stylesheet" media="screen">
<style>
.container {
max-width: 1000px;
}
</style>
</head>
<body>
<div class="container">
<div class="row">
<div class="col-sm-5 col-sm-offset-1">
<h1>Wordcount</h1>
<br>
<form role="form" method="POST" action="/">
<div class="form-group">
<input type="text" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;">
</div>
<button type="submit" class="btn btn-default">Submit</button>
</form>
<br>
{% for error in errors %}
<h4>{{ error }}</h4>
{% endfor %}
<br>
</div>
<div class="col-sm-5 col-sm-offset-1">
{% if results %}
<h2>Frequencies</h2>
<br>
<div id="results">
<table class="table table-striped" style="max-width: 300px;">
<thead>
<tr>
<th>Word</th>
<th>Count</th>
</tr>
</thead>
{% for result in results%}
<tr>
<td>{{ result[0] }}</td>
<td>{{ result[1] }}</td>
</tr>
{% endfor %}
</table>
</div>
{% endif %}
</div>
</div>
</div>
<br><br>
<script src="//code.jquery.com/jquery-1.11.0.min.js"></script>
<script src="//netdna.bootstrapcdn.com/bootstrap/3.1.1/js/bootstrap.min.js"></script>
</body>
</html>
$ gunicorn -w 4 -b 127.0.0.1:5001 aka:app ... Starting gunicorn 19.4.5 ... Listening at: http://127.0.0.1:5001 (724)
We can run the gunicorn with pm2:
$ pm2 start gunicorn_aka.sh

where the gunicorn_aka.sh is:
exec gunicorn -w 4 -b 127.0.0.1:5001 aka:app
To setup a reverse proxy, we need to load the "proxy_http" module in Apache:
$ sudo a2enmod proxy_http
The reverse proxy virtual host configuration in "/etc/apache2/sites-available/akadrone.example.com.conf" looks like this:
<VirtualHost *:80>
ServerName www.akadrone.example.com
ServerAlias akadrone.example.com
ProxyPreserveHost On
ProxyPass / http://127.0.0.1:5001/
#ProxyPassReverse / http://127.0.0.1:5001/
ErrorLog /var/www/akadrone.com/logs/error.log
CustomLog /var/www/akadrone.com/logs/access.log combined
LogLevel warn
ServerSignature Off
</VirtualHost>
The "ProxyPreserveHost" will make sure the “Host” header in the request is not rewritten. The lack of a "ProxyPassReverse" will make sure that there is no rewriting done on the response.
Now we can access our site with port 80:
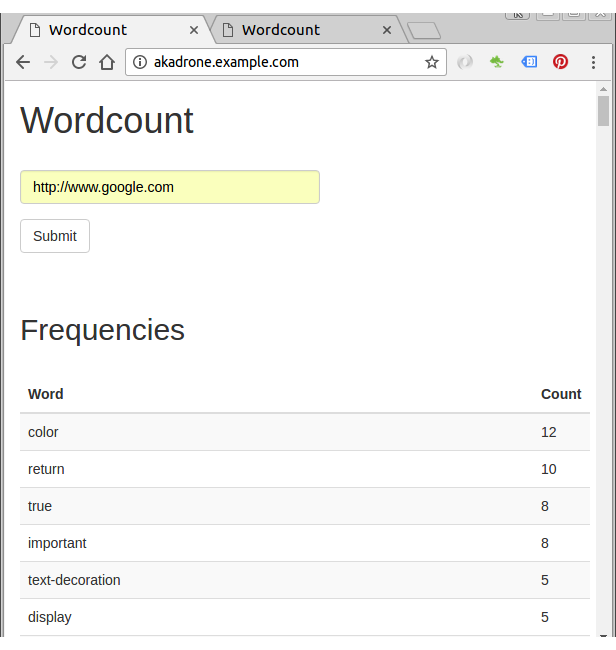
If lots of users all hitting our site at once to get word counts, the counting takes longer to process.
So, instead of counting the words after each user makes a request, we need to use a queue to process this in the backend.
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization