Coding Questions VI - 2024
Majority of problems in this post (#6) are from Codility for Programmers.
Most of the codes in this post are optimized to get O(N) not O(N*N).
A non-empty list a consisting of N integers is given. The consecutive elements of list a represent consecutive cars on a road. The list a contains only 0s and/or 1s where 0 represents a car traveling east, 1 represents a car traveling west.
What we want is to count passing cars. For example, with a = [0,1,0,1,1], we have five pairs of passing cars: (0, 1), (0, 3), (0, 4), (2, 3), (2, 4). So, it should return 5. Note that the function should return −1 if the number of pairs of passing cars exceeds 1,000,000,000.
def prefix_sum_passing_cars(a):
passing = 0
west = 0
for index in range(len(a)-1,-1,-1):
if a[index] == 0:
passing += west
print('index=%s a[%s]=%s west=%s passing=%s' %(index,index, a[index], west, passing))
else:
west += 1
print('index=%s a[%s]=%s west=%s passing=%s' %(index,index, a[index], west, passing))
if passing > 1000000000:
return -1
return passing
a = [0,1,0,1,1]
print(a)
print(prefix_sum_passing_cars(a))
N = 100
a = [0,1]*N
print(a)
print(prefix_sum_passing_cars(a))
Output:
[0, 1, 0, 1, 1] index=4 a[4]=1 west=1 passing=0 index=3 a[3]=1 west=2 passing=0 index=2 a[2]=0 west=2 passing=2 index=1 a[1]=1 west=3 passing=2 index=0 a[0]=0 west=3 passing=5 5 [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1] index=199 a[199]=1 west=1 passing=0 index=198 a[198]=0 west=1 passing=1 index=197 a[197]=1 west=2 passing=1 index=196 a[196]=0 west=2 passing=3 index=195 a[195]=1 west=3 passing=3 index=194 a[194]=0 west=3 passing=6 ... index=3 a[3]=1 west=99 passing=4851 index=2 a[2]=0 west=99 passing=4950 index=1 a[1]=1 west=100 passing=4950 index=0 a[0]=0 west=100 passing=5050 5050
We want to count the number of integers divisible by k in range [A,B]. For example, for A = 6, B = 11 and k = 2, your function should return 3, because there are three numbers divisible by 2 within the range [6,11], namely 6, 8 and 10.
The first try could be like this one (not efficient for BIG numbers):
def solution(A, B, K):
count = 0
for i in range(A,B+1):
if i % K == 0:
count += 1
return count
A = 10; B = 10; K = 20
for i in range(A,B+1):
print(i, i%K)
print(solution(A,B,K))
A = 6; B = 11; K = 2
print(solution(A,B,K))
A = 6; B = 12; k = 2
print(solution(A,B,K))
K = 20000
import random
A = 6; B = random.randint(A,K); K = 2
print(solution(A,B,K))
Better one looks like this (no loop!):
def solution(A, B, K):
if A % K == 0:
return (B//K)-(A//K)+1
return (B//K)-(A//K)
A = 6; B = 11; K = 2
print(solution(A,B,K))
A = 6; B = 12; k = 2
print(solution(A,B,K))
K = 3000000000
import random
A = random.randint(0,K); B = random.randint(A,K); K = random.randint(0,B)
print('A=%s B=%s K=%s' %(A,B,K))
print(solution(A,B,K))
Output:
3 4 A=1862515586 B=2800297761 K=1273784499 1
Given a list of edges, find out if we can make a triangle from the list of edges. If we can, return 1. Otherwise, return 0:
def solution(A):
B = sorted(A)
i = 0
edges = []
while i < len(B)-2:
if B[i] + B[i+1] > B[i+2]:
return 1
i += 1
return 0
A = [10,2,5,1,8,20]
print(A)
print(solution(A))
N = 100
import random
A = [random.randint(1,N) for x in range(4)]
print(A)
print(solution(A))
N = 1000000
import random
A = [random.randint(1,N) for x in range(3)]
print(A)
print(solution(A))
Output:
[10, 2, 5, 1, 8, 20] 1 [94, 24, 75, 57] 1 [620574, 190688, 307319] 0
Given a list of integers, write a function that returns an index of a dominant element (more than half the number of elements). If no dominant element, returns -1:
def solution(A):
from collections import defaultdict
d = defaultdict(int)
half = len(A)/2
for a in A:
d[a] += 1
for k,v in d.items():
if v > half:
return(A.index(k))
return -1
A = [3,4,3,2,3,-1,3,3]
print(solution(A))
N = 2147483647
N = 10
import random
A = [random.randint(-1,0) for x in range(N//2)]
print(A)
print(solution(A))
N = 30
import random
A = [random.randint(-1,5) for x in range(N)]
print(A)
print(solution(A))
Output:
0 [-1, 0, 0, -1, -1] 0 [2, 3, 0, 0, 1, 0, 4, 2, 5, 0, 3, 4, 0, 2, 4, 5, 1, 4, 3, 4, 3, -1, 4, 5, 1, 4, 3, -1, 4, 3] -1
Given integer N which represents the area of a rectangle. Write a function that returns a minimum perimeter. For example, given integer N = 30, rectangles of area 30 are:
- (1, 30), with a perimeter of 62
- (2, 15), with a perimeter of 34
- (3, 10), with a perimeter of 26
- (5, 6), with a perimeter of 22
def solution(N):
factors = []
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
prime_applied = False
for p in primes:
if N % p == 0:
end = N // p
prime_applied = True
break
if not prime_applied:
end = int(N**0.5)
for i in range(1, end+1):
if N % i == 0:
factors.append(i)
factors.append(N)
#print(factors)
MIN = (N+1)*2
st = 0
end = len(factors)-1
# left + right toward the center
while st <= end:
perimeter = (factors[st]+factors[end])*2
if perimeter < MIN:
MIN = perimeter
#print('st=%s end=%s, perimeter=%s' %(st,end,perimeter))
st += 1
end -= 1
return MIN
N = 30
print(solution(N))
N = 101
print(solution(N))
Output:
[1, 2, 3, 5, 6, 10, 15, 30] st=0 end=7, perimeter=62 st=1 end=6, perimeter=34 st=2 end=5, perimeter=26 st=3 end=4, perimeter=22 22 [1, 101] st=0 end=1, perimeter=204 204
If we add more case in the driver:
N = 30 print(solution(N)) N = 101 print(solution(N)) N = 4564320 print(solution(N)) N = 15486451 print(solution(N)) N = 100000000 print(solution(N)) N = 982451653 print(solution(N)) N = 1000000000 print(solution(N))
The new output:
22 204 8552 30972904 40000 1964903308 126500
Note that the last one takes a while, so we may have to write a more efficient code.
With A = [1,4,-3], we get permutations:
[(1, 1), (1, 4), (1, -3), (4, 4), (4, -3), (-3, -3)]
The min-abs-sum is '1'
With A = [-8,4,5,-10,3], we get permutations:
[(-8, -8), (-8, 4), (-8, 5), (-8, -10), (-8, 3), (4, 4), (4, 5), (4, -10), (4, 3), (5, 5), (5, -10), (5, 3), (-10, -10), (-10, 3), (3, 3)]
The min-abs-sum is '3'
Here is the code with complexity O(N^2):
def solution(A):
from itertools import combinations_with_replacement
MIN = 2**32-1
pairs = list(combinations_with_replacement(A,2))
print(pairs)
for p in pairs:
s = abs(p[0]+p[1])
if s < MIN:
MIN = s
return MIN
A = [1,4,-3]
print(solution(A))
A = [-8,4,5,-10,3]
print(solution(A))
Output:
[(1, 1), (1, 4), (1, -3), (4, 4), (4, -3), (-3, -3)] 1 [(-8, -8), (-8, 4), (-8, 5), (-8, -10), (-8, 3), (4, 4), (4, 5), (4, -10), (4, 3), (5, 5), (5, -10), (5, 3), (-10, -10), (-10, 3), (3, 3)] 3
Better code with O(N logN) is:
def solution(A):
left = 0
right = len(A)-1
A.sort()
MN = 2000000000
while left <= right:
MN = min(MN, abs( A[left]+A[right]) )
if abs(A[left]) > abs(A[right]):
left += 1
else:
right -= 1
return MN
A = [1,4,-3]
print(solution(A))
A = [-8,4,5,-10,3]
print(solution(A))
Note that we use sort() before traversing the list.
Output:
1 3
A frog wants to get to the other side of the road. The frog is currently located at position X and wants to get to a position greater than or equal to Y. The small frog always jumps a fixed distance, D.
Count the minimal number of jumps that the small frog must perform to reach its target.
def solution(X,Y,D):
jumps = (Y-X+D-1)//D
return jumps
X = 10; Y=85; D =30
print(solution(X,Y,D))
X = 10; Y=10; D =30
print(solution(X,Y,D))
Output:
3 0
Determine whether a given string of parentheses (single type of '(' and ')') is properly nested.
def isProperlyNested(S):
stack = []
for s in S:
if s == '(':
stack.append(s)
elif s ==')':
if stack and stack[-1] == '(':
stack.pop()
else:
stack.append(s)
else:
pass
# non-empty stack, NOT properly nested
if stack:
return S, stack, False
# properly nested
else:
return S, stack, True
S = "(()(())())"
print(isProperlyNested(S))
S = "())"
print(isProperlyNested(S))
S = ")("
print(isProperlyNested(S))
S = "+)(+()"
print(isProperlyNested(S))
S = "(12)(34)"
print(isProperlyNested(S))
S = ""
print(isProperlyNested(S))
Output:
('(()(())())', [], True)
('())', [')'], False)
(')(', [')', '('], False)
('+)(+()', [')', '('], False)
('(12)(34)', [], True)
('', [], True)
Determine whether a given string of parentheses (multiple types) is properly nested.
def isProperlyNested(S):
stack = []
for s in S:
if s == '{' or s == '(' or s == '[':
stack.append(s)
elif s =='}':
if stack and stack[-1] == '{':
stack.pop()
else:
stack.append(s)
elif s ==')':
if stack and stack[-1] == '(':
stack.pop()
else:
stack.append(s)
elif s == ']':
if stack and stack[-1] == '[':
stack.pop()
else:
stack.append(s)
else:
pass
# non-empty stack, NOT properly nested
if stack:
return S, stack, False
# properly nested
else:
return S, stack, True
S = "(()(())())"
print(isProperlyNested(S))
S = "())"
print(isProperlyNested(S))
S = "(()){}[]"
print(isProperlyNested(S))
S = ")("
print(isProperlyNested(S))
S = "+)(+()"
print(isProperlyNested(S))
S = "(12)(34)"
print(isProperlyNested(S))
S = ""
print(isProperlyNested(S))
Output:
('(()(())())', [], True)
('())', [')'], False)
('(()){}[]', [], True)
(')(', [')', '('], False)
('+)(+()', [')', '('], False)
('(12)(34)', [], True)
('', [], True)
Left shift of a list:
# left rotation (shift)
# right shift (feed negative values for K)
def solution(A, K):
if len(A) == 0 or K == 0: return A
# Normalize the moving distance (to avoid multiple rotation when K > len(A))
K = K % len(A)
# For right shift (use negative index)
return A[K:] + A[:K]
A = [3, 8, 9, 7, 6]; K = 1
print(solution(A,K)) # [8, 9, 7, 6, 3]
A = [3, 8, 9, 7, 6]; K = 3
print(solution(A,K)) # [7, 6, 3, 8, 9]
A = [0, 0, 0]; K = 1
print(solution(A,K)) # [0, 0, 0]
A = [1, 2, 3, 4]; K = 4
print(solution(A,K)) # [1, 2, 3, 4]
A = [1, 1, 2, 3, 5]; K = 42
print(solution(A,K)) # [2, 3, 5, 1, 1]
Output:
[8, 9, 7, 6, 3] [7, 6, 3, 8, 9] [0, 0, 0] [1, 2, 3, 4] [2, 3, 5, 1, 1]
For a right-shift, we can feed '-' value of K. For example "solutions(A,-K)".
Find out the maximum possible profit from the daily price of log:
A[0] = 23171 A[1] = 21011 A[2] = 21123 A[3] = 21366 A[4] = 21013 A[5] = 21367
Detailed description of the problem: MaxProfit
This is one of the problems that we conjure up O(N*N) code initially like this:
def solution(A):
MX = 0
for i in range(len(A)):
j = i
while j < len(A) - 1:
MX = max(MX, A[j+1]-A[i])
j += 1
return MX
The key to get O(N) code is to keep track of 'mn_price' while we traversing the log!
def solution(A):
mx_profit = 0
mx_price = 0
mn_price = 200000
for p in A:
mn_price = min(mn_price, p)
mx_profit = max(mx_profit, p - mn_price)
return mx_profit
A = [23171,21011,21123,21366,21013,21367]
print(solution(A))
Output:
356
We get the max_profix of 356 from '21367-21011'
We need to return the number of fish that will stay alive.
The value in list B with 0 means a fish flowing upstream, and with 1 means a fish flowing downstream.
The value in list A is the size (power) of the fish.
Problem description: fish
All downstream fishes should be put on a stack. Any upstream swimming fish has to be checked with all fishes on the stack. If there is no fish on the stack, the fish survives. If the stack has some downstream fishes at the end with no upstream fish, the fishes are lucky.
def solution(A,B):
stack = []
alive = 0
for i in range(len(A)):
# downstream
if B[i] == 1:
stack.append(A[i])
# upstream
else:
while stack:
# stack fish stay alive, remain in stack
if stack[-1] > A[i]:
break
# stack fish smaller is eaten, pop()
else:
stack.pop()
else:
alive += 1
return len(stack)+alive
A = [4,3,2,1,5]
B = [0,1,0,0,0] # 0: upstream 1:downstream
print(solution(A,B))
A = [8]
B = [0] # 0: upstream 1:downstream
print(solution(A,B))
A = [8,4]
B = [1,0] # 0: upstream 1:downstream
print(solution(A,B))
Output:
2 1 1
For a given height of walls: H = [8,8,5,7,9,8,7,4,8]
We need to return the minimum number of blocks needed to build it.
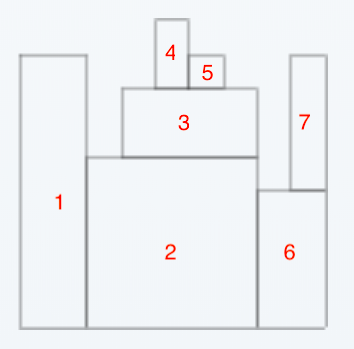
Problem description: Stonewall
def solution(H):
stack = []
count = 0
for i,h in enumerate(H):
while len(stack) != 0 and stack[-1] > h:
stack.pop()
if stack and stack[-1] == h:
# stack already has a block of height, h
pass
else:
count += 1
stack.append(h)
return count
H = [8,8,5,7,9,8,7,4,8]
print(solution(H))
H = [1,2,3,2,1]
print(solution(H))
Output:
7 3
Return the number of factors or divisors for a given integer N.
The first solution:
def solution(N):
factors = []
for i in range(1,N+1):
if N % i == 0:
factors.append(i)
return len(factors)
N = 36
print(solution(N))
Output:
9
But with the simple code, the code takes a while to get the solution for N = 12! = 479001600. So, we may want to write a more efficient code for big input.
We can use idea of the picture below:

Picture from here.
We can double the number of factors(divisors) counter up to sqrt(N). If i*i = N, we can just add 1 to the counter.
For example, we can traverse 1,2,3,...,36 for N=36. For 1,2,3,4: double. Skip 5 because it's '36' is not divisible by 5. And then comes '6', which is 6*6 = 36. So, for 6, we add 1 to the counter. So, counter = 4*2 + 1 = 9.
def solution(N):
count = 0
for i in range(1, N+1):
if i*i > N:
break
if N % i == 0:
if i*i < N:
count += 2
elif i*i == N:
count += 1
return count
N = 25
print(solution(N))
N = 36
print(solution(N))
Output:
3 9
Replace '.' with '!' for files under directories. Recursively. We may want to write a backup file (.bak) as well.
import os
import fileinput
home = os.path.expanduser('~')
top = os.path.join(home,'Documents/TEMP4')
files = []
for root, dirnames, filenames in os.walk(top):
for f in filenames:
files.append(os.path.join(root,f))
# replace a string
search_text = '.'
replace_text = '!'
for filename in files:
if '.bak' not in filename:
with open(filename, 'r') as f:
filedata = f.read()
with open(filename+'.bak', 'w') as f:
f.write(filedata)
filedata = filedata.replace(search_text, replace_text)
with open(filename, 'w') as f:
f.write(filedata)
Current file:
Few are those who see with their own eyes and feel with their own hearts. Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
A new file:
Few are those who see with their own eyes and feel with their own hearts! Imagination is more important than knowledge! Knowledge is limited! Imagination encircles the world!
Directory list:
$ ls mytext.txt mytext.txt.bak
Similar to the previous example, here, we want to replace a string in files. In this case, we want to have the list of files modified.
import os
search = '12345'
replace = '54321'
modified_files = []
for root, dirs, files in os.walk('/Users/kihyuckhong/Documents/TEMP/SUB'):
for fname in files:
fname = os.path.join(root, fname)
with open(fname,'r') as f:
content = f.readline()
if search in content:
modified_files.append(fname)
print(modified_files)
Output:
['/Users/kihyuckhong/Documents/TEMP/SUB/SUB1/t1.txt', '/Users/kihyuckhong/Documents/TEMP/SUB/SUB2/t2.txt']
We can do the same result with a shell command, 1-liner:
$ find ./ -type f -name "*.txt" -exec sed -i "s/12345/54321/g" {} \; -print
./SUB/SUB1/t1.txt
./SUB/SUB2/t2.txt
The "{}" has the result from the "find" command, and the "find" command need to know when the arguments of exec are terminated. So, we added ';'. The escape ('\') is needed because ';' has its own meaning within a shell.
On MacOS, however, the sed -i requires backup, which is an option in Linux. So, it should look like this on MacOS (note that no space between i and '.bak'):
$ find ./ -type f -name "*.txt" -exec sed -i'.bak' "s/12345/54321/g" {} \; -print
Don't like the require backup option? Then, install gnu-sed, and use gsed instead:
$ brew install gnu-sed
$ find ./ -type f -name "*.txt" -exec gsed -i "s/12345/54321/g" {} \; -print
Don't like the escape ("\")?. Then, we can use quote("") instead as shown below:
$ find ./ -type f -name "*.txt" -exec sed -i "s/12345/54321/g" {} ";" -print
Note that we can use xargs as well with the "find" and "sed":
$ find . -type f -name "*.txt" -print0 | xargs -0 sed -i '' 's/12345/54321/g'
find . -type f -name '*.txt'finds, in the current directory (.) and below, all regular files (-type f) whose names end in .txt- The "print0" puts ASCII NUL instead of '\n', and this requires "-0" after "xargs".
- passes the output of that command (a list of filenames) to the next command
xargsgathers up those filenames and hands them one by one tosedsed -i '' -e 's/abcde/12345/g'means "edit the file in place, without a backup (here, zero length string, '' is provides), and make the following substitution (s/abcde/12345) multiple times per line (/g)" (see man sed)- From How can I do a recursive find and replace from the command line?
We have a json file:
[
{
"name": "John Doe",
"email": "jd@aol.com"
},
{
"name": "Jane Doe",
"email": "jane@gmail.com"
},
{
"name": "John Doe",
"email": "johndoe@yahoo.com"
},
{
"name": "John Doe Jr.",
"email": "johndoejr@abc.com"
}
]
It consists of "name" and "email" pairs. Some of them has more than one emails. So, we need to make a data something like (name, [list of emails]).
Here is the code:
import json
from collections import defaultdict
data = json.load(open("./email.json","r"))
print("data=",data)
emails = []
for d in data:
emails.append((d['name'],d['email']))
d = defaultdict(list)
for k,v in emails:
d[k].append(v)
print(d.items())
Output:
data= [{'name': 'John Doe', 'email': 'jd@aol.com'}, {'name': 'Jane Doe', 'email': 'jane@gmail.com'}, {'name': 'John Doe', 'email': 'johndoe@yahoo.com'}, {'name': 'John Doe Jr.', 'email': 'johndoejr@abc.com'}]
dict_items([('John Doe', ['jd@aol.com', 'johndoe@yahoo.com']), ('Jane Doe', ['jane@gmail.com']), ('John Doe Jr.', ['johndoejr@abc.com'])])
Note that there are couple of ways of initializing a dictionary with list type.
- Using defaultdict():
from collections import defaultdict s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)] d = defaultdict(list) for k,v in s: d[k].append(v) print(d.items()) - Using setdefault() which is a little bit slower than using defaultdict():
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)] d = {} for k,v in s: d.setdefault(k,[]).append(v) print(d.items())
Both of them give us the same output:
dict_items([('yellow', [1, 3]), ('blue', [2, 4]), ('red', [1])])
To check if a year is leap year or not:
- The year can be evenly divided by 4, is a leap year, unless:
- The year can be evenly divided by 100, it is NOT a leap year, unless:
- The year is also evenly divisible by 400. Then it is a leap year.
So, the years 2000 and 2400 are leap years, while 1800, 1900, 2100, 2200, 2300 and 2500 are NOT leap years.
def isLeapYear(y):
if y % 4 == 0:
if y % 100 == 0:
if y % 400 == 0:
return True
else:
return False
return True
else:
return False
year = input("Enter year:")
print(isLeapYear(int(year)))
Output:
Enter year:2000 True Enter year:1800 False Enter year:2100 False Enter year:2300 False Enter year:2018 False Enter year:2020 True Enter year:2500 False
Given names with all letters are lowercase. Capitalize the names.
def capitalize(names):
new_names = []
for name in names:
n_list = [w[0].upper()+w[1:] for w in name.split()]
new_names.append(" ".join(n_list))
return new_names
names = ['john steinbeck', 'earest hemingway']
new_names = capitalize(names)
print("new_names=",new_names)
Output:
new_names= ['John Steinbeck', 'Earest Hemingway']
We can use "title()" method:
def capitalize(names):
new_names = []
for name in names:
new_names.append(name.title())
return new_names
names = ['john steinbeck', 'earest hemingway']
new_names = capitalize(names)
print("names=",new_names)
We have a log file which has log data aggregated from several applications. We want to which app has the most error code (LogLevel) for a given date. The log file looks like this:
Date Time App LogLevel MSG 20190201 1200 app1 WARN "404 page not found" 20190201 1300 app1 ERROR "503 service not available" 20190201 1400 app2 ERROR "502 Bad Gateway" 20190201 1430 app4 ERROR "502 Bad Gateway" 20190201 1431 app2 ERROR "502 Bad Gateway" 20190201 1500 app5 ERROR "504 Gateway time out" 20190201 1501 app3 ERROR "504 Gateway time out" 20190201 1502 app3 ERROR "504 Gateway time out" 20190201 1503 app1 ERROR "504 Gateway time out" 20190201 1507 app3 ERROR "504 Gateway time out" 20190202 1600 app2 ERROR "503 service not available" 20190203 1700 app4 ERROR "502 Bad Gateway" 20190203 1800 app3 ERROR "504 Gateway time out"
The code:
DATE = '20190201'
LOGLEVEL = 'ERROR'
with open('log.txt','r') as f:
freq = {}
for line in f:
s = line.split()
if s[0] == DATE and s[3] == LOGLEVEL:
if s[2] in freq.keys():
freq[s[2]] += 1
else:
freq[s[2]] = 1
print("app frequency :", freq)
sf = sorted(freq.items(), key = lambda x:x[1], reverse = True)
print("sorted : ", sf)
print("the most frequent app : ", sf[0][0])
Output:
app frequency : {'app1': 2, 'app2': 2, 'app4': 1, 'app5': 1, 'app3': 3}
sorted : [('app3', 3), ('app1', 2), ('app2', 2), ('app4', 1), ('app5', 1)]
the most frequent app : app3
With bash:
DATE='20190201'
LOGLEVEL='ERROR'
freq=()
while read line; do
array=( $line )
if [[ ${array[0]} == $DATE && ${array[3]} == $LOGLEVEL ]]
then
freq+=("${array[2]}")
fi
done < "$HOME/log.txt"
printf "%s\n" "${freq[@]}" | sort | uniq -c | sort -rn | head -n 1 | awk '{print "ans = " $2}'
Output:
ans = app3
Or with just shell commands:
$ cat log.txt | grep "20190201" | grep "ERROR" | awk '{print $3}'| \
sort | uniq -c | sort -nr | head -n 1 | awk '{print $2}'
app3
$ cat log.txt | awk '/20190201/ && /ERROR/ {print $3}' \
| sort | uniq -c | sort -nr | head -n 1 | awk '{print $2}'
app3
How we get a status_code from a site?
import requests
r = requests.get('https://bogotobogo.com/')
if r.status_code == 200:
print("OK : status_code = %d" %r.status_code)
else:
print("Not OK : status_code = %d" %r.status_code)
Output:
OK : status_code = 200
With different URI:
import requests
r = requests.get('https://bogotobogo.com/404')
if r.status_code == 200:
print("OK : status_code = %d" %r.status_code)
else:
print("Not OK : status_code = %d" %r.status_code)
Output:
Not OK : status_code = 404
If we use shell script:
#!/bin/bash
status_code=$(curl -s -o /dev/null -w "%{http_code}" https://bogotobogo.com/)
if [ $status_code -eq 200 ]; then
echo "OK : status_code = $status_code"
else
echo "Not OK : status_code = $status_code"
fi
Output:
OK : status_code = 200
Find the largest (maximum) hourglass sum in a given 2D array.
a = [
[1, 1, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0],
[0, 0, 2, 4, 4, 0],
[0, 0, 0, 2, 0, 0],
[0, 0, 1, 2, 4, 0]]
The input array has the following hourglasses:

This is the hourglass that has the maximum:

a = [
[1, 1, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0],
[0, 0, 2, 4, 4, 0],
[0, 0, 0, 2, 0, 0],
[0, 0, 1, 2, 4, 0]]
mx = -2147483648
n = len(a)
for i in range(n):
for j in range(n):
if i == 0 or i == n-1 or j==0 or j == n-1:
pass
else:
mx = max(mx,(a[i-1][j-1]+a[i-1][j]+a[i-1][j+1]+a[i][j]+a[i+1][j-1]+a[i+1][j]+a[i+1][j+1]))
print(mx)
In the code, we get the indices around the element at the center of an hourglass. Note that the center elements are inside of the boundary elements. So, we skipped the boundaries in the for-loops. In the 6x6 matrix, we have 16 (4x4) hourglasses.
Output:
19
For an input like this, it will give an answer = 28:
a = [
[-9, -9, -9, 1, 1, 1],
[0, -9, 0, 4, 3, 2],
[-9, -9, -9, 1, 2, 3],
[0, 0, 8, 6, 6, 0],
[0, 0, 0, -2, 0, 0],
[0, 0, 1, 2, 4, 0]]
That's from this hourglass:
0 4 3 1 6 6 0
We want to find out the minimum number of bribes that took place to get the queue into its current state!
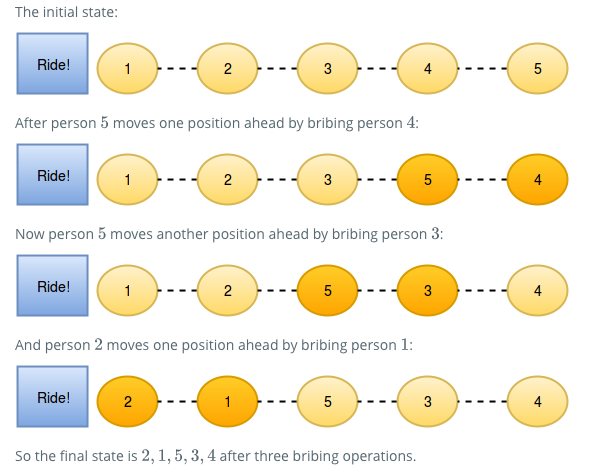
Pic. from https://www.hackerrank.com/challenges
def bribe(a):
count = 0
for i in range(len(a)):
if a[i] - (i+1) > 2:
return "Too chaotic"
elif a[i] > (i+1):
count += (a[i] - (i+1))
else:
pass
return count
a = [[2,1,5,3,4], [2,5,1,3,4]]
for _ in a:
out = bribe(_)
print("%s: %s" %(_,out))
Output:
[2, 1, 5, 3, 4]: 3 [2, 5, 1, 3, 4]: Too chaotic
Starting with a 1-indexed array of zeros and a list of operations, for each operation add a value to each of the array element between two given indices, inclusive. Once all operations have been performed, return the maximum value in the array.
For example, the length of our array of zero, and with the following input for the operations:
n = 10 operation = [[1,5,3], [4,8,7], [6,9,1]]
Starting from zero valued list, the operations should look like this:
index-> 1 2 3 4 5 6 7 8 9 10 [0,0,0, 0, 0,0,0,0,0, 0] [3,3,3, 3, 3,0,0,0,0, 0] [3,3,3,10,10,7,7,7,0, 0] [3,3,3,10,10,8,8,8,1, 0]
So, we get the maximum value of 10 as an answer.
Here is the code:
def added(operation,n):
a = [0]*n
for op in operation:
st = op[0]-1; end = op[1]-1; add = op[2]
for i in range(st, end+1):
a[i] += add
return a, max(a)
op1 = [[1,5,3], [4,8,7], [6,9,1]]
n1 = 10
a1, mx1 = added(op1,n1)
print(a1, ' max1 =', mx1)
op2 = [[1,2,100], [2,5,100], [3,4,100]]
n2 = 5
a2, mx2 = added(op2,n2)
print(a2, ' max2 =', mx2)
Harold is a kidnapper who wrote a ransom note, but now he is worried it will be traced back to him through his handwriting. He found a magazine and wants to know if he can cut out whole words from it and use them to create an untraceable replica of his ransom note. The words in his note are case-sensitive and he must use only whole words available in the magazine. He cannot use substrings or concatenation to create the words he needs.
Given the words in the magazine and the words in the ransom note, print Yes if he can replicate his ransom note exactly using whole words from the magazine; otherwise, print 'No'.
For example, the note is "Attack at dawn". The magazine contains only "attack at dawn". The magazine has all the right words, but there's a case mismatch. The answer is 'No'.
Problem source: https://www.hackerrank.com/challenges
Here is the code:
def yes_or_no(mag, ran):
print('magazine=',mag, ', ransom=',ran)
# construct dictionary for word count
mag_dict = {}.fromkeys(set(mag.split()),0)
for k,v in mag_dict.items():
mag_dict[k] += 1
# loop through the ransom words and compare it with the words in the magazine
ran_list = ran.split()
for r in ran_list:
if r not in mag_dict.keys():
print('%s is not in magzaine' %r)
return 'No'
if mag_dict[r] == 0:
print('%s is not available from magzaine any more' %r)
return 'No'
else:
print('Found %s in the magazine' %r)
mag_dict[r] -= 1
return 'yes'
# input
magine_ransom = [('give me one grand today night','give one grand today'),
('give me one grand today night','Give one grand today'),
('two times three is not four','two times two is four'),
('ive got a lovely bunch of coconuts','ive got some coconuts')]
for item in magine_ransom:
result = yes_or_no(item[0], item[1])
print(result)
print()
Output:
magazine= give me one grand today night , ransom= give one grand today Found give in the magazine Found one in the magazine Found grand in the magazine Found today in the magazine yes magazine= give me one grand today night , ransom= Give one grand today Give is not in magzaine No magazine= two times three is not four , ransom= two times two is four Found two in the magazine Found times in the magazine two is not available from magzaine any more No magazine= ive got a lovely bunch of coconuts , ransom= ive got some coconuts Found ive in the magazine Found got in the magazine some is not in magzaine No
In the code, we constructed our own dictionary. But we can use "collections.Counter(list)" instead:
def yes_or_no(mag, ran):
print('magazine=',mag, ', ransom=',ran)
# use Counter(list)
from collections import Counter
counter = Counter(mag.split())
print(counter)
# loop through the ransom words and compare it with the words in the magazine
ran_list = ran.split()
for r in ran_list:
if r not in counter.keys():
print('%s is not in magzaine' %r)
return 'No'
if counter[r] == 0:
print('%s is not available from magzaine any more' %r)
return 'No'
else:
print('Found %s in the magazine' %r)
counter[r] -= 1
return 'yes'
# input
magine_ransom = [('give me one grand today night','give one grand today'),
('give me one grand today night','Give one grand today'),
('two times three is not four','two times two is four'),
('ive got a lovely bunch of coconuts','ive got some coconuts')]
for item in magine_ransom:
result = yes_or_no(item[0], item[1])
print(result)
print()
The collections.Counter() works like this:
>>> from collections import Counter
>>>
>>> myList = [1,1,2,3,4,5,3,2,3,4,2,1,2,3]
>>> print Counter(myList)
Counter({2: 4, 3: 4, 1: 3, 4: 2, 5: 1})
>>>
>>> print Counter(myList).items()
[(1, 3), (2, 4), (3, 4), (4, 2), (5, 1)]
>>>
>>> print Counter(myList).keys()
[1, 2, 3, 4, 5]
>>>
>>> print Counter(myList).values()
[3, 4, 4, 2, 1]
For a given array and we need to find number of tripets of indices such that the elements at those indices are in geometric progression for a given common ratio and i < j < k.
Problem source: https://www.hackerrank.com/challenges
def triplet(r,a):
print('r=',r,' a=',a)
# index triplets
tr = []
n = len(a)
for i in range(n):
for j in range(i+1, n):
if a[j]/a[i] == r:
for k in range(j+1, n):
if a[k]/a[j] == r:
tr.append((i,j,k))
return tr, len(tr)
r1 = 2
a1 = [1,2,2,4]
print(triplet(r1,a1))
r2 = 3
a2 = [1,3,9,9,27,81]
print(triplet(r2,a2))
r3 = 5
a3 = [1,5,5,25,125]
print(triplet(r3,a3))
Output:
r= 2 a= [1, 2, 2, 4] ([(0, 1, 3), (0, 2, 3)], 2) r= 3 a= [1, 3, 9, 9, 27, 81] ([(0, 1, 2), (0, 1, 3), (1, 2, 4), (1, 3, 4), (2, 4, 5), (3, 4, 5)], 6) r= 5 a= [1, 5, 5, 25, 125] ([(0, 1, 3), (0, 2, 3), (1, 3, 4), (2, 3, 4)], 4)
- Python Coding Questions I
- Python Coding Questions II
- Python Coding Questions III
- Python Coding Questions IV
- Python Coding Questions V
- Python Coding Questions VI
- Python Coding Questions VII
- Python Coding Questions VIII
- Python Coding Questions IX
- Python Coding Questions X
List of codes Q & A
- Merging two sorted list
- Get word frequency - initializing dictionary
- Initializing dictionary with list
- map, filter, and reduce
- Write a function f() - yield
- What is __init__.py?
- Build a string with the numbers from 0 to 100, "0123456789101112..."
- Basic file processing: Printing contents of a file - "with open"
- How can we get home directory using '~' in Python?
- The usage of os.path.dirname() & os.path.basename() - os.path
- Default Libraries
- range vs xrange
- Iterators
- Generators
- Manipulating functions as first-class objects
- docstrings vs comments
- using lambdda
- classmethod vs staticmethod
- Making a list with unique element from a list with duplicate elements
- What is map?
- What is filter and reduce?
- *args and **kwargs
- mutable vs immutable
- Difference between remove, del and pop on lists
- Join with new line
- Hamming distance
- Floor operation on integers
- Fetching every other item in the list
- Python type() - function
- Dictionary Comprehension
- Sum
- Truncating division
- Python 2 vs Python 3
- len(set)
- Print a list of file in a directory
- Count occurrence of a character in a Python string
- Make a prime number list from (1,100)
- Reversing a string - Recursive
- Reversing a string - Iterative
- Reverse a number
- Output?
- Merging overlapped range
- Conditional expressions (ternary operator)
- Packing Unpacking
- Function args
- Unpacking args
- Finding the 1st revision with a bug
- Which one has higher precedence in Python? - NOT, AND , OR
- Decorator(@) - with dollar sign($)
- Multi-line coding
- Recursive binary search
- Iterative binary search
- Pass by reference
- Simple calculator
- iterator class that returns network interfaces
- Converting domain to ip
- How to count the number of instances
- Python profilers - cProfile
- Calling a base class method from a child class that overrides it
- How do we find the current module name?
- Why did changing list 'newL' also change list 'L'?
- Constructing dictionary - {key:[]}
- Colon separated sequence
- Converting binary to integer
- 9+99+999+9999+...
- Calculating balance
- Regular expression - findall
- Chickens and pigs
- Highest possible product
- Implement a queue with a limited size
- Copy an object
- Filter
- Products
- Pickle
- Overlapped Rectangles
- __dict__
- Fibonacci I - iterative, recursive, and via generator
- Fibonacci II - which method?
- Fibonacci III - find last two digits of Nth Fibonacci number
- Write a Stack class returning Max item at const time A
- Write a Stack class returning Max item at const time B
- Finding duplicate integers from a list - 1
- Finding duplicate integers from a list - 2
- Finding duplicate integers from a list - 3
- Reversing words 1
- Parenthesis, a lot of them
- Palindrome / Permutations
- Constructing new string after removing white spaces
- Removing duplicate list items
- Dictionary exercise
- printing numbers in Z-shape
- Factorial
- lambda
- lambda with map/filter/reduce
- Number of integer pairs whose difference is K
- iterator vs generator
- Recursive printing files in a given directory
- Bubble sort
- What is GIL (Global Interpreter Lock)?
- Word count using collections
- Pig Latin
- List of anagrams from a list of words
- lamda with map, filer and reduce functions
- Write a code sending an email using gmail
- histogram 1 : the frequency of characters
- histogram 2 : the frequency of ip-address
- Creating a dictionary using tuples
- Getting the index from a list
- Looping through two lists side by side
- Dictionary sort with two keys : primary / secondary keys
- Writing a file downloaded from the web
- Sorting csv data
- Reading json file
- Sorting class objects
- Parsing Brackets
- Printing full path
- str() vs repr()
- Missing integer from a sequence
- Polymorphism
- Product of every integer except the integer at that index
- What are accessors, mutators, and @property?
- N-th to last element in a linked list
- Implementing linked list
- Removing duplicate element from a list
- List comprehension
- .py vs .pyc
- Binary Tree
- Print 'c' N-times without a loop
- Quicksort
- Dictionary of list
- Creating r x c matrix
- Transpose of a matrix
- str.isalpha() & str.isdigit()
- Regular expression
- What is Hashable? Immutable?
- Convert a list to a string
- Convert a list to a dictionary
- List - append vs extend vs concatenate
- Use sorted(list) to keep the original list
- list.count()
- zip(list,list) - join elements of two lists
- zip(list,list) - weighted average with two lists
- Intersection of two lists
- Dictionary sort by value
- Counting the number of characters of a file as One-Liner
- Find Armstrong numbers from 100-999
- Find GCF (Greatest common divisor)
- Find LCM (Least common multiple)
- Draws 5 cards from a shuffled deck
- Dictionary order by value or by key
- Regular expression - re.split()
- Regular expression : re.match() vs. re.search()
- Regular expression : re.match() - password check
- Regular expression : re.search() - group capturing
- Regular expression : re.findall() - group capturin
- Prime factors : n = products of prime numbers
- Valid IPv4 address
- Sum of strings
- List rotation - left/right
- shallow/deep copy
- Converting integer to binary number
- Creating a directory and a file
- Creating a file if not exists
- Invoking a python file from another
- Sorting IP addresses
- Word Frequency
- Printing spiral pattern from a 2D array - I. Clock-wise
- Printing spiral pattern from a 2D array - II. Counter-Clock-wise
- Find a minimum integer not in the input list
- I. Find longest sequence of zeros in binary representation of an integer
- II. Find longest sequence of zeros in binary representation of an integer - should be surrounded with 1
- Find a missing element from a list of integers
- Find an unpaired element from a list of integers
- Prefix sum : Passing cars
- Prefix sum : count the number of integers divisible by k in range [A,B]
- Can make a triangle?
- Dominant element of a list
- Minimum perimeter
- MinAbsSumOfTwo
- Ceiling - Jump Frog
- Brackets - Nested parentheses
- Brackets - Nested parentheses of multiple types
- Left rotation - list shift
- MaxProfit
- Stack - Fish
- Stack - Stonewall
- Factors or Divisors
- String replace in files 1
- String replace in files 2
- Using list as the default_factory for defaultdict
- Leap year
- Capitalize
- Log Parsing
- Getting status_code for a site
- 2D-Array - Max hourglass sum
- New Year Chaos - list
- List (array) manipulation - list
- Hash Tables: Ransom Note
- Count Triplets with geometric progression
- Strings: Check if two strings are anagrams
- Strings: Making Anagrams
- Strings: Alternating Characters
- Special (substring) Palindrome
- String with the same frequency of characters
- Common Child
- Fraudulent Activity Notifications
- Maximum number of toys
- Min Max Riddle
- Poisonous Plants with Pesticides
- Common elements of 2 lists - Complexity
- Get execution time using decorator(@)
- Conver a string to lower case and split using decorator(@)
- Python assignment and memory location
- shallow copy vs deep copy for compound objects (such as a list)
- Generator with Fibonacci
- Iterator with list
- Second smallest element of a list
- *args, **kargs, and positional args
- Write a function, fn('x','y',3) that returns ['x1', 'y1', 'x2', 'y2', 'x3', 'y3']
- sublist or not
- any(), all()
- Flattening a list
- Select an element from a list
- Circularly identical lists
- Difference between two lists
- Reverse a list
- Split a list with a step
- Break a list and make chunks of size n
- Remove duplicate consecutive elements from a list
- Combination of elements from two lists
- Adding a sublist
- Replace the first occurence of a value
- Sort the values of the first list using the second list
- Transpose of a matrix (nested list)
- Binary Gap
- Powerset
- Round Robin
- Fixed-length chunks or blocks
- Accumulate
- Dropwhile
- Groupby
- Simple product
- Simple permutation
- starmap(fn, iterable)
- zip_longest(*iterables, fillvalue=None)
- What is the correct way to write a doctest?
- enumerate(iterable, start=0)
- collections.defaultdict - grouping a sequence of key-value pairs into a dictionary of lists
- What is the purpose of the 'self' keyword when defining or calling instance methods?
- collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
- zipped
- What is key difference between a set and a list?
- What does a class's init() method do?
- Class methods
- Permutations and combinations of ['A','B','C']
- Sort list of dictionaries by values
- Return a list of unique words
- hashlib
- encode('utf-8')
- Reading in CSV file
- Count capital letters in a file
- is vs ==
- Create a matrix : [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- Binary to integer and check if it's the power of 2
- urllib.request.urlopen() and requests
- Game statistics
- Chess - pawn race
- Decoding a string
- Determinant of a matrix - using numpy.linalg.det()
- Revenue from shoe sales - using collections.Counter()
- Rangoli
- Unique characters
- Valid UID
- Permutations of a string in lexicographic sorted order
- Nested list
- Consecutive digit count
- Find a number that occurs only once
- Sorting a two-dimensional array
- Reverse a string
- Generate random odd numbers in a range
- Shallow vs Deep copy
- Transpose matrix
- Are Arguments in Python Passed by Value or by Reference?
- re: Is a string alphanumeric?
- reversed()
- Caesar's cipher, or shift cipher, Caesar's code, or Caesar shift
- Every other words
- re: How can we check if an email address is valid or not?
- re: How to capture temperatures of a text
- re.split(): How to split a text.
- How can we merge two dictionaries?
- How can we combine two dictionaries?
- What is the difference between a generator and a list?
- Pairs of a given array A whose sum value is equal to a target value N
- Adding two integers without plus
- isinstance() vs type()
- What is a decorator?
- In Python slicing, what does my_list[-3:2:-2] slice do?
- Revisit sorting dict - counting chars in a text file
- re: Transforming a date format using re.sub
- How to replace the newlines in csv file with tabs?
- pandas.merge
- How to remove duplicate charaters from a string?
- Implement a class called ComplexNumber
- Find a word frequency
- Get the top 3 most frequent characters of a string
- Just seen and ever seen
- Capitalizing the full name
- Counting Consequitive Characters
- Calculate Product of a List of Integers Provided using input()
- How many times a substring appears in a string
- Hello, first_name last_name
- String validators
- Finding indices that a char occurs in a list
- itertools combinations
Python tutorial
Python Home
Introduction
Running Python Programs (os, sys, import)
Modules and IDLE (Import, Reload, exec)
Object Types - Numbers, Strings, and None
Strings - Escape Sequence, Raw String, and Slicing
Strings - Methods
Formatting Strings - expressions and method calls
Files and os.path
Traversing directories recursively
Subprocess Module
Regular Expressions with Python
Regular Expressions Cheat Sheet
Object Types - Lists
Object Types - Dictionaries and Tuples
Functions def, *args, **kargs
Functions lambda
Built-in Functions
map, filter, and reduce
Decorators
List Comprehension
Sets (union/intersection) and itertools - Jaccard coefficient and shingling to check plagiarism
Hashing (Hash tables and hashlib)
Dictionary Comprehension with zip
The yield keyword
Generator Functions and Expressions
generator.send() method
Iterators
Classes and Instances (__init__, __call__, etc.)
if__name__ == '__main__'
argparse
Exceptions
@static method vs class method
Private attributes and private methods
bits, bytes, bitstring, and constBitStream
json.dump(s) and json.load(s)
Python Object Serialization - pickle and json
Python Object Serialization - yaml and json
Priority queue and heap queue data structure
Graph data structure
Dijkstra's shortest path algorithm
Prim's spanning tree algorithm
Closure
Functional programming in Python
Remote running a local file using ssh
SQLite 3 - A. Connecting to DB, create/drop table, and insert data into a table
SQLite 3 - B. Selecting, updating and deleting data
MongoDB with PyMongo I - Installing MongoDB ...
Python HTTP Web Services - urllib, httplib2
Web scraping with Selenium for checking domain availability
REST API : Http Requests for Humans with Flask
Blog app with Tornado
Multithreading ...
Python Network Programming I - Basic Server / Client : A Basics
Python Network Programming I - Basic Server / Client : B File Transfer
Python Network Programming II - Chat Server / Client
Python Network Programming III - Echo Server using socketserver network framework
Python Network Programming IV - Asynchronous Request Handling : ThreadingMixIn and ForkingMixIn
Python Coding Questions I
Python Coding Questions II
Python Coding Questions III
Python Coding Questions IV
Python Coding Questions V
Python Coding Questions VI
Python Coding Questions VII
Python Coding Questions VIII
Python Coding Questions IX
Python Coding Questions X
Image processing with Python image library Pillow
Python and C++ with SIP
PyDev with Eclipse
Matplotlib
Redis with Python
NumPy array basics A
NumPy Matrix and Linear Algebra
Pandas with NumPy and Matplotlib
Celluar Automata
Batch gradient descent algorithm
Longest Common Substring Algorithm
Python Unit Test - TDD using unittest.TestCase class
Simple tool - Google page ranking by keywords
Google App Hello World
Google App webapp2 and WSGI
Uploading Google App Hello World
Python 2 vs Python 3
virtualenv and virtualenvwrapper
Uploading a big file to AWS S3 using boto module
Scheduled stopping and starting an AWS instance
Cloudera CDH5 - Scheduled stopping and starting services
Removing Cloud Files - Rackspace API with curl and subprocess
Checking if a process is running/hanging and stop/run a scheduled task on Windows
Apache Spark 1.3 with PySpark (Spark Python API) Shell
Apache Spark 1.2 Streaming
bottle 0.12.7 - Fast and simple WSGI-micro framework for small web-applications ...
Flask app with Apache WSGI on Ubuntu14/CentOS7 ...
Fabric - streamlining the use of SSH for application deployment
Ansible Quick Preview - Setting up web servers with Nginx, configure enviroments, and deploy an App
Neural Networks with backpropagation for XOR using one hidden layer
NLP - NLTK (Natural Language Toolkit) ...
RabbitMQ(Message broker server) and Celery(Task queue) ...
OpenCV3 and Matplotlib ...
Simple tool - Concatenating slides using FFmpeg ...
iPython - Signal Processing with NumPy
iPython and Jupyter - Install Jupyter, iPython Notebook, drawing with Matplotlib, and publishing it to Github
iPython and Jupyter Notebook with Embedded D3.js
Downloading YouTube videos using youtube-dl embedded with Python
Machine Learning : scikit-learn ...
Django 1.6/1.8 Web Framework ...
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization