Flask app 3 - word counts with Redis task queue

In this tutorial, we'll implement a Redis task queue to handle the text processing that because if lots of users all hitting our site at once to get word counts, the counting takes longer to process.
So, instead of counting the words after each user makes a request, we need to use a queue to process this in the backend.
New tools used in this tutorial:
- Redis (3.2.3) - to install see http://redis.io/download
- Python Redis (2.10.5)
- RQ (Redis Queue) (0.6.0) - a simple Python library for queueing jobs and processing them in the background with workers.
$ sudo pip install redis
$ pip install redis==2.10.5 rq==0.6.0 $ pip freeze > requirements.txt
Github source : akadrone-flask
Let's create a worker process to listen for queued tasks.
Here is worker.py:
import os
import redis
from rq import Worker, Queue, Connection
listen = ['default']
redis_url = os.getenv('REDISTOGO_URL', 'redis://localhost:6379')
conn = redis.from_url(redis_url)
if __name__ == '__main__':
with Connection(conn):
worker = Worker(list(map(Queue, listen)))
worker.work()
Here, we listened for a queue called default and established a connection to the Redis server on localhost:6379.
Start the Redis server:
$ redis-server ... The server is now ready to accept connections on port 6379
In another terminal:
$ python worker.py 23:28:05 RQ worker u'rq:worker:K-Notebook.7562' started, version 0.6.0 23:28:05 Cleaning registries for queue: default 23:28:05 23:28:05 *** Listening on default...
Now we need to update our app (aka.py) to send jobs to the queue:
import os
import requests
import operator
import re
import nltk
from flask import Flask, render_template, request
from flask.ext.sqlalchemy import SQLAlchemy
from stop_words import stops
from collections import Counter
from bs4 import BeautifulSoup
from rq import Queue
from rq.job import Job
from worker import conn
app = Flask(__name__)
app.config.from_object('config')
app_settings = app.config['APP_SETTINGS']
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://localhost/wordcount_dev'
db = SQLAlchemy(app)
q = Queue(connection=conn)
from models import *
def count_and_save_words(url):
errors = []
try:
r = requests.get(url)
except:
errors.append(
"Unable to get URL. Please make sure it's valid and try again."
)
return {"error": errors}
# text processing
raw = BeautifulSoup(r.text).get_text()
nltk.data.path.append('./nltk_data/') # set the path
tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens)
# remove punctuation, count raw words
nonPunct = re.compile('.*[A-Za-z].*')
raw_words = [w for w in text if nonPunct.match(w)]
raw_word_count = Counter(raw_words)
# stop words
no_stop_words = [w for w in raw_words if w.lower() not in stops]
no_stop_words_count = Counter(no_stop_words)
# save the results
try:
result = Result(
url=url,
result_all=raw_word_count,
result_no_stop_words=no_stop_words_count
)
db.session.add(result)
db.session.commit()
return result.id
except:
errors.append("Unable to add item to database.")
return {"error": errors}
@app.route('/', methods=['GET', 'POST'])
def index():
results = {}
if request.method == "POST":
# get url that the person has entered
url = request.form['url']
if 'http://' not in url[:7]:
url = 'http://' + url
job = q.enqueue_call(
func=count_and_save_words, args=(url,), result_ttl=5000
)
print(job.get_id())
return render_template('index.html', results=results)
@app.route("/results/<job_key>", methods=['GET'])
def get_results(job_key):
job = Job.fetch(job_key, connection=conn)
if job.is_finished:
return str(job.result), 200
else:
return "Nay!", 202
if __name__ == '__main__':
app.run()
The line q = Queue(connection=conn) set up a Redis connection and initialized a queue based on that connection.
Move the text processing functionality out of our index route and into a new function called count_and_save_words(). This function accepts one argument, a URL, which we will pass to it when we call it from our index route.
We used the queue that we initialized earlier. It is calling enqueue_call() function. This is adding a new job to the queue and that job is running the count_and_save_words() function with the URL as the argument.
The result_ttl=5000 line argument tells RQ how long (5,000 seconds) to hold the result of the job. Then, we print out the job id to the terminal. This id is needed to see if the processing job is done.
Note that the id number is generated when we add the results to the database.
# save the results
try:
result = Result(
url=url,
result_all=raw_word_count,
result_no_stop_words=no_stop_words_count
)
db.session.add(result)
db.session.commit()
return result.id
Now we may want to test our implementation.
Let's run our server first:
$ python manage.py runserver ... * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) ... b9a81d99-94bf-43b5-9270-01bcac47b72b ...
Then, in another terminal, run our worker module:
$ python worker.py ... 16:11:52 default: Job OK (148c7c07-7102-41a4-a5f5-4517daa840b8) 16:11:52 Result is kept for 5000 seconds 16:11:52 16:11:52 *** Listening on default...
Then use that id in the /results/ endpoint - i.e., http://localhost:5000/results/b9a81d99-94bf-43b5-9270-01bcac47b72b.

We want the actual JSON formatted results from the database. So, let's refactor the route in aka.py:
import os
import requests
import operator
import re
import nltk
from flask import Flask, render_template, request
from flask.ext.sqlalchemy import SQLAlchemy
from stop_words import stops
from collections import Counter
from bs4 import BeautifulSoup
from rq import Queue
from rq.job import Job
from worker import conn
from flask import jsonify
app = Flask(__name__)
app.config.from_object('config')
app_settings = app.config['APP_SETTINGS']
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://localhost/wordcount_dev'
db = SQLAlchemy(app)
q = Queue(connection=conn)
from models import *
def count_and_save_words(url):
errors = []
try:
r = requests.get(url)
except:
errors.append(
"Unable to get URL. Please make sure it's valid and try again."
)
return {"error": errors}
# text processing
raw = BeautifulSoup(r.text).get_text()
nltk.data.path.append('./nltk_data/') # set the path
tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens)
# remove punctuation, count raw words
nonPunct = re.compile('.*[A-Za-z].*')
raw_words = [w for w in text if nonPunct.match(w)]
raw_word_count = Counter(raw_words)
# stop words
no_stop_words = [w for w in raw_words if w.lower() not in stops]
no_stop_words_count = Counter(no_stop_words)
# save the results
try:
result = Result(
url=url,
result_all=raw_word_count,
result_no_stop_words=no_stop_words_count
)
db.session.add(result)
db.session.commit()
return result.id
except:
errors.append("Unable to add item to database.")
return {"error": errors}
@app.route('/', methods=['GET', 'POST'])
def index():
results = {}
if request.method == "POST":
# get url that the person has entered
url = request.form['url']
if 'http://' not in url[:7]:
url = 'http://' + url
job = q.enqueue_call(
func=count_and_save_words, args=(url,), result_ttl=5000
)
print(job.get_id())
return render_template('index.html', results=results)
@app.route("/results/<job_key>", methods=['GET'])
def get_results(job_key):
job = Job.fetch(job_key, connection=conn)
if job.is_finished:
result = Result.query.filter_by(id=job.result).first()
results = sorted(
result.result_no_stop_words.items(),
key=operator.itemgetter(1),
reverse=True
)[:10]
return jsonify(results)
else:
return "Nay!", 202
if __name__ == '__main__':
app.run()
Note that we added the import:
from flask import jsonify
Let's test it again. In one terminal:
$ python worker.py 14:14:24 RQ worker u'rq:worker:K-Notebook.8359' started, version 0.6.0 14:14:24 Cleaning registries for queue: default 14:14:24 14:14:24 *** Listening on default...
On another terminal:
$ ./gunicorn_aka.sh ... Starting gunicorn 19.6.0 ... Listening at: http://127.0.0.1:5000 (9486)
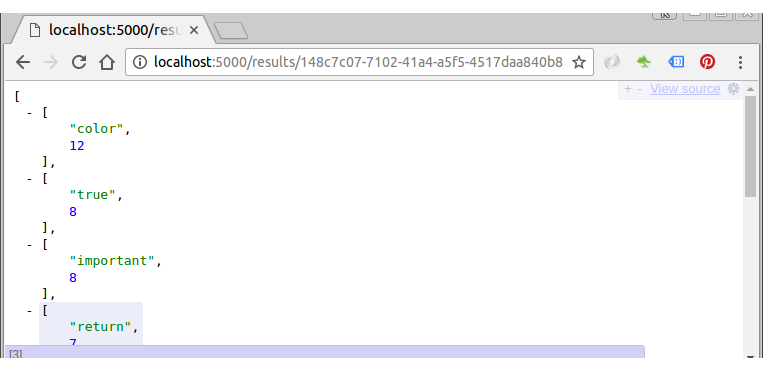
After we submit a url (i.e. google.com), we get id on the 2nd terminal were we ran 'gunicorn':
148c7c07-7102-41a4-a5f5-4517daa840b8
Then, we add '/results/id' to the url:
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization