Algorithms - Heap Sort
Heapsort is a comparison-based sorting algorithm, and is part of the selection sort family.
Although somewhat slower in practice on most machines than a good implementation of quicksort, it has the advantage of a more favorable worst-case O(n log n) runtime. Heapsort is an in-place algorithm, but is not a stable sort.
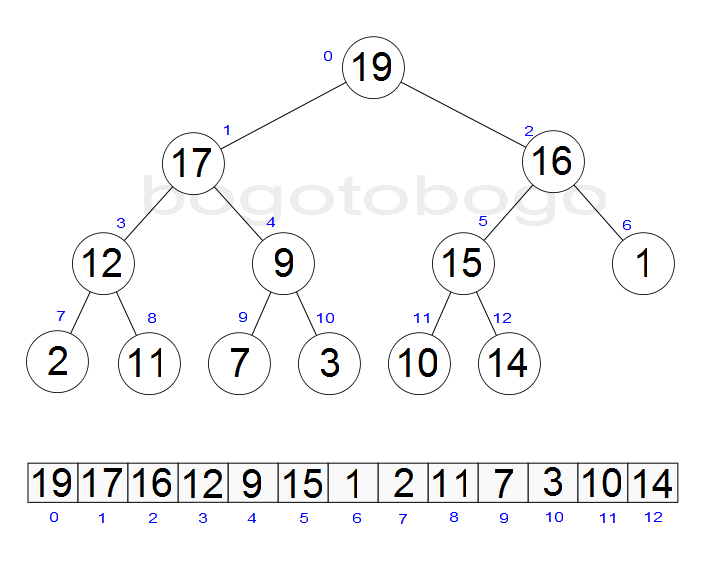
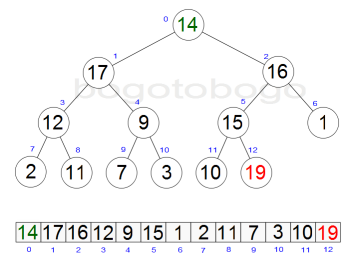
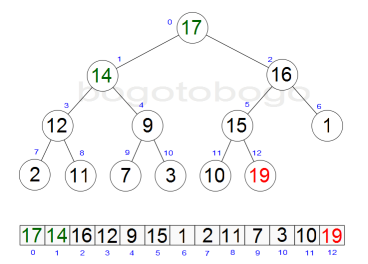
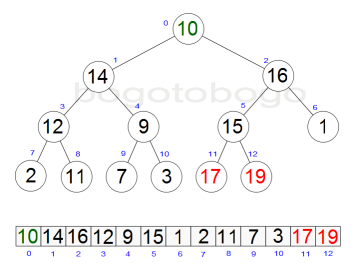
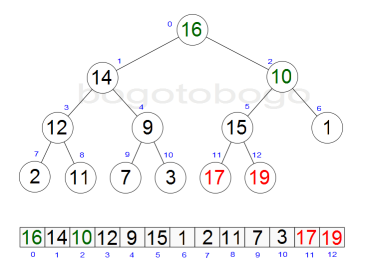
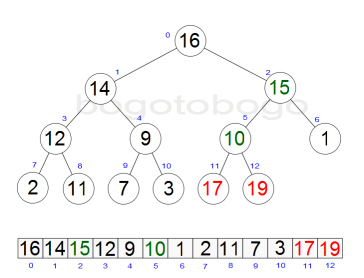
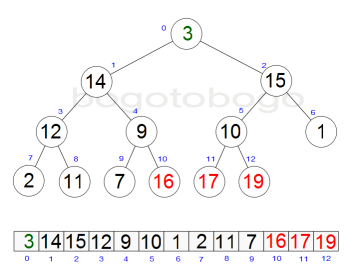
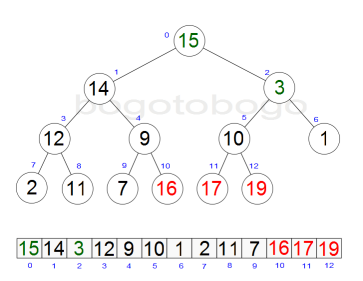
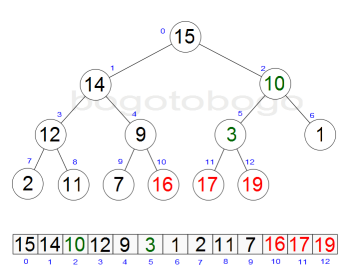
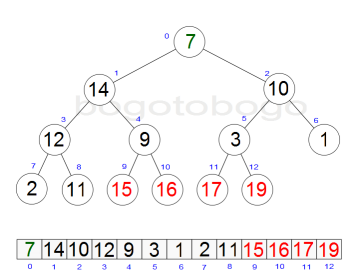
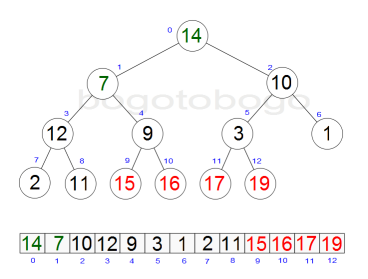
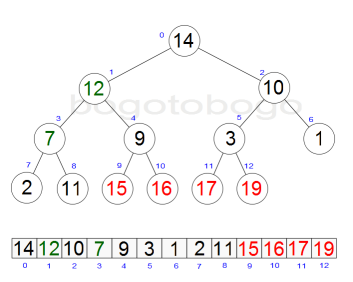
It works by determining the largest (or smallest) element of the list, placing that at the end of the list, then continuing with the rest of the list, but accomplishes this task efficiently by using a data structure called a heap, a special type of binary tree. Once the data list has been made into a heap, the root node is guaranteed to be the largest element. It is removed and placed at the end of the list, then the heap is rearranged so the largest element remaining moves to the root . Using the heap, finding the next largest element takes O(log n) time, instead of O(n) for a linear scan as in simple selection sort. This allows Heapsort to run in O(n log n) time.
We need at least n-1 comparisons to find the largest in an array of n elements. But we want to minimize the number of elements that are compared directly to it. In sports tournament, we find the best team from n teams without matches of all teams. Heap sort shows how to apply this behavior to sort a set of elements.
Heapsort begins by building a heap out of the data set, and then removing the largest item and placing it at the end of the partially sorted array. After removing the largest item, it reconstructs the heap, removes the largest remaining item, and places it in the next open position from the end of the partially sorted array. This is repeated until there are no items left in the heap and the sorted array is full. Elementary implementations require two arrays - one to hold the heap and the other to hold the sorted elements.
The heap's invariant is preserved after each extraction, so the only cost is that of extraction. During extraction, the only space required is that needed to store the heap. To achieve constant space overhead, the heap is stored in the part of the input array not yet sorted.
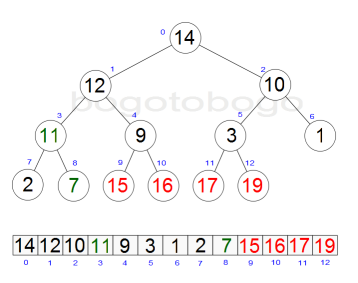
A heap is a binary tree whose structure ensures two properties:
- Shape property
A leaf node at depth k>0 can exist only if all 2k-1 nodes at depth k-1 exist. Additionally, nodes at a partially filled level must be added from left to right. - Heap property
Each node in the tree contains a value greater than or equal to either of its two children, if it has any.
C++ code
#include <iostream>
using namespace std;
void siftDown( int *a, int k, int N);
void swap(int *m, int *n)
{
int tmp;
tmp = *m;
*m = *n;
*n = tmp;
}
void heapsort( int a[], int N){
/* heapify */
for (int k = N/2; k >= 0; k--) {
siftDown( a, k, N);
}
while (N-1 > 0) {
/* swap the root(maximum value) of the heap
with the last element of the heap */
swap(a[N-1], a[0]);
/* put the heap back in max-heap order */
siftDown(a, 0, N-1);
/* N-- : decrease the size of the heap by one
so that the previous max value will
stay in its proper placement */
N--;
}
}
void siftDown( int *a, int k, int N){
while ( k*2 + 1 < N ) {
/* For zero-based arrays, the children are 2*i+1 and 2*i+2 */
int child = 2*k + 1;
/* get bigger child if there are two children */
if ((child + 1 < N) && (a[child] < a[child+1])) child++;
if (a[k] < a[child]) { /* out of max-heap order */
swap( a[child], a[k] );
/* repeat to continue sifting down the child now */
k = child;
}
else
return;
}
}
int main()
{
int i;
int a[] = {19, 17, 16, 12, 9, 15, 1, 2, 11, 7, 3, 10, 14};
const size_t sz = sizeof(a)/sizeof(a[0]);
for (i = 0; i < sz; i++)
cout << a[i] << " ";
cout << endl;
cout << "----------------------------------" << endl;
heapsort(a, sz);
for (i = 0; i < sz; i++)
cout << a[i] << " ";
cout << endl;
return 0;
}
Output:
19 17 16 12 9 15 1 2 11 7 3 10 14 ---------------------------------- 1 2 3 7 9 10 11 12 14 15 16 17 19
For min-heap, we can just switch to > from <:
void siftDown( int *a, int k, int N){
while ( k*2 + 1 < N ) {
/* For zero-based arrays, the children are 2*i+1 and 2*i+2 */
int child = 2*k + 1;
/* get smaller child if there are two children */
if ((child + 1 < N) && (a[child] > a[child+1])) child++;
if (a[k] > a[child]) { /* out of min-heap order */
swap( a[child], a[k] );
/* repeat to continue sifting down the child now */
k = child;
}
else
return;
}
}
Then, the output will be something like this:
19 17 16 12 9 15 1 2 11 7 3 10 14 ---------------------------------- 19 17 16 15 14 12 11 10 9 7 3 2 1
How to build heap, sift down, sift up, insert, and remove to get the Maximum?
Please visit Heap-based Priority Queue.
Q: If you have all the companies that are traded, and live inputs are coming of which company is being traded and what is the volume, how do you maintain the data, so that you can carry out operation of giving the top 10 most traded companies by volume of shares most efficiently. (quiz source
A: Since we need to extract top ten companies at any moment, we keep that info using min-heap. It's not a good idea of using max heap because when a new transaction comes, we need to iterate all the top 10 companies to see if has more volume than any element in the heap tree. By maintaining min heap, we only need to compare the root which is the min. If a new transaction is greater than the min, we rebalance the tree, but if not, we do no have to touch the tree.
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization