Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Here is the description from Apache Drill:
Drill supports a variety of NoSQL databases and file systems, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores.
For example, you can join a user profile collection in MongoDB with a directory of event logs in Hadoop.
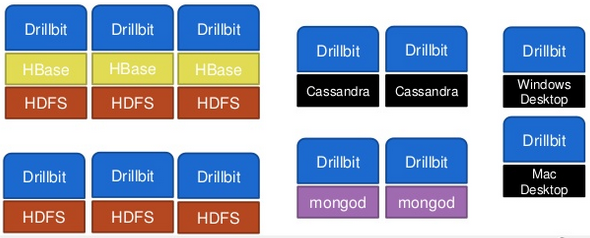
picture source : Drilling into Data with Apache Drill
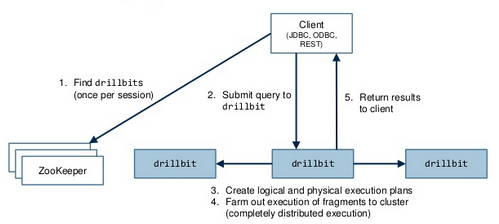
- Drillbit is Apache drill's daemon that runs on each node of the cluster.
- It uses ZooKeeper for all communication in the cluster and maintains cluster membership.
- It is responsible for accepting requests from the client, processing the queries, and returning results to the client.
- Drillbit that receives the request from the client is called foreman.
Java 7 or 8 should be installed before we use Drill. Let's check:
$ java -version openjdk version "1.8.0_111" OpenJDK Runtime Environment (build 1.8.0_111-8u111-b14-2ubuntu0.16.04.2-b14) OpenJDK 64-Bit Server VM (build 25.111-b14, mixed mode)
If not installed, we need to install Java:
$ sudo apt-get update $ sudo apt-get install default-jdk
Download from Apache Drill site, and extract it to /usr/local/:
$ wget http://www-us.apache.org/dist/drill/drill-1.8.0/apache-drill-1.8.0.tar.gz $ sudo tar xvzf apache-drill-1.8.0.tar.gz -C /usr/local
Now, we can start Drill.
To start the Drill shell in embedded mode, we want to use the drill-embedded command. Internally, the command uses a jdbc connection string and identifies the local node as the ZooKeeper node.
Before we start Drill, let's navigate to the Drill installation directory (/usr/local/apache-drill-1.8.0) and issue the following command to start the Drill shell:
root@laptop:/usr/local/apache-drill-1.8.0# bin/drill-embedded OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0 Nov 10, 2016 10:27:25 PM org.glassfish.jersey.server.ApplicationHandler initialize INFO: Initiating Jersey application, version Jersey: 2.8 2014-04-29 01:25:26... apache drill 1.8.0 "a little sql for your nosql" 0: jdbc:drill:zk=local>
Embedded mode requires less configuration & it is preferred for testing purpose.
As we can see from the message, we got 0: jdbc:drill:zk=local> prompt which suggests the drill-embedded command uses a jdbc connection string and identifies the local node as the ZooKeeper node.
Here is the description about the prompt:
- 0 is the number of connections to Drill, which can be only one in embedded node.
- jdbc is the connection type.
- zk=local zk=local means the local node substitutes for the ZooKeeper node. In other words, Drill in embedded mode does not require installation of ZooKeeper.
Note that drillbit (Drill daemon) starts automatically in embedded mode.
Now the Drill shell is running:
$ netstat -nlpt|grep 8047 tcp6 0 0 :::8047 :::* LISTEN -
Let's open the Drill Web Console that is available at localhost:8047:
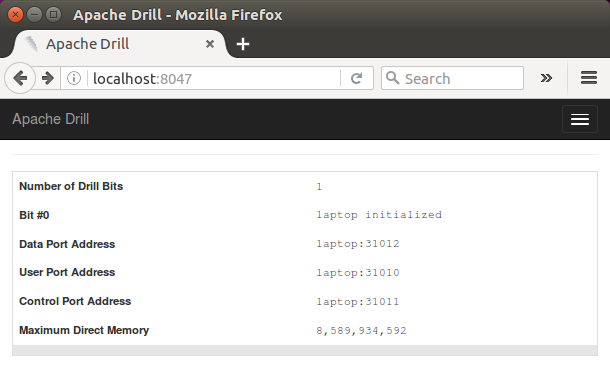
To exit the Drill shell, issue !quit command:<./p>
0: jdbc:drill:zk=local> !quit Closing: org.apache.drill.jdbc.impl.DrillConnectionImpl root@laptop:/usr/local/apache-drill-1.8.0/bin#
To install Drill on nodes in the cluster, we need to configure a cluster ID and add Zookeeper information.
So, we need install Apache ZooKeeper which coordinates and synchronizes configuration information of nodes of a distributed system.
Since the ZooKeeper package is available in Ubuntu's default repositories, we can install it using apt-get:
$ sudo apt-get install zookeeperd ... update-alternatives: using /etc/zookeeper/conf_example to provide /etc/zookeeper/conf (zookeeper-conf) in auto mode Setting up zookeeperd (3.4.8-1) ... ...
Once installed, ZooKeeper will be started as a daemon automatically. By default, it listens on port 2181:
$ sudo netstat -nlpt | grep ':2181' tcp6 0 0 :::2181 :::* LISTEN 13827/java
At the telnet prompt, type in ruok and press ENTER. If everything's fine, ZooKeeper will say imok and end the Telnet session.
$ telnet localhost 2181 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. ruok imokConnection closed by foreign host.
Or we can check the status:
# /usr/share/zookeeper/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /etc/zookeeper/conf/zoo.cfg Mode: standalone
We may want to a user (here, ubuntu) to the zookeeper group so that we can write zookeeper_server.pid under /var/lib/zookeeper directory (called dataDir), which is needed when we try to stop zookeeper process via the "pid":
$ sudo usermod -a -G zookeeper ubuntu $ groups ubuntu ubuntu : ubuntu adm dialout cdrom floppy sudo audio dip video plugdev netdev lxd zookeeper
Running ZooKeeper in standalone mode is convenient for evaluation and development, and testing. In production, however, we should run ZooKeeper in replicated mode. A replicated group of servers in the same application is called a quorum, and in replicated mode, all servers in the quorum have copies of the same configuration file.
The directory structure of the ZooKeeper looks like this:
Stop the ZooKeeper that's been running when we installed it and run again:
# /usr/share/zookeeper/bin/zkServer.sh stop # /usr/share/zookeeper/bin/zkServer.sh start ZooKeeper JMX enabled by default Using config: /etc/zookeeper/conf/zoo.cfg Starting zookeeper ... STARTED
Note: ZooKeeper configuration file is /etc/zookeeper/conf/zoo.cfg.
Here is the directory structure of the installed Drill:
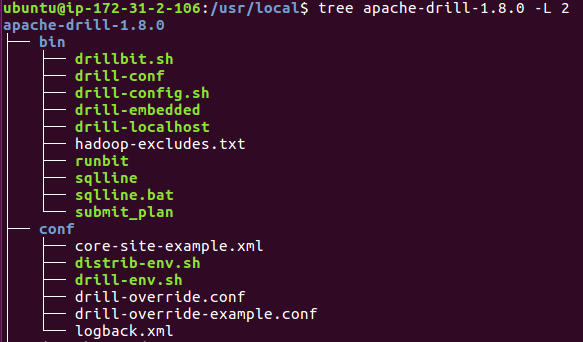
In conf/drill-override.conf, we need to specify the Drill cluster ID (cluster-id), and provide ZooKeeper host names and port numbers in zk.connect to configure a connection to our ZooKeeper quorum.
If we install Drill on multiple nodes, assign the same cluster ID to each Drill node so that all Drill nodes share the same ID. The default ZooKeeper port on the open source version of Apache Drill is 2181:
drill.exec:{
cluster-id: "<mydrillcluster>",
zk.connect: "<zkhostname1>:<port>,<zkhostname2>:<port>,<zkhostname3>:<port>"
}
Our configuration :
drill.exec: {
cluster-id: "drillbits1",
#zk.connect: "localhost:2181"
zk.connect: "54.183.167.85:2181"
}
In distributed mode, drill runs on one or more nodes in a clustered environment. Running a ZooKeeper quorum is required.
To use Drill in distributed mode, we first need to start a Drill daemon (Drillbit) on each node in the cluster. So, before attempting to connect a client we should start the Drillbit using drillbit.sh command:
Note that we can use the drillbit.sh command to perform other tasks as well such as:
- Check the status of the Drillbit.
- Stop or restart a Drillbit.
- Configure a Drillbit to restart by default.
The syntax of drillbit.sh command looks like this:
drillbit.sh [--config] (start|stop|status|restart|autorestart)
Let's start it.
We have two distributed nodes:
- server.1: 54.183.167.85 (private: 172.31.2.106)
- server.2: 54.67.74.118 (private: 172.31.13.111)
We run Drill on each servers:
ubuntu@ip-172-31-2-106:/usr/local/apache-drill-1.8.0$ sudo su root@ip-172-31-2-106:/usr/local/apache-drill-1.8.0# root@ip-172-31-2-106:/usr/local/apache-drill-1.8.0# ./bin/drillbit.sh start Starting drillbit, logging to /usr/local/apache-drill-1.8.0/log/drillbit.out
Same on the 2nd server:
ubuntu@ip-172-31-13-111:/usr/local/apache-drill-1.8.0# sudo ./bin/drillbit.sh start
To run Zookeepers, we use the same command on each machine:
ubuntu@ip-172-31-2-106:~$ sudo /usr/share/zookeeper/bin/zkServer.sh start ubuntu@ip-172-31-13-111:~$ sudo /usr/share/zookeeper/bin/zkServer.sh start
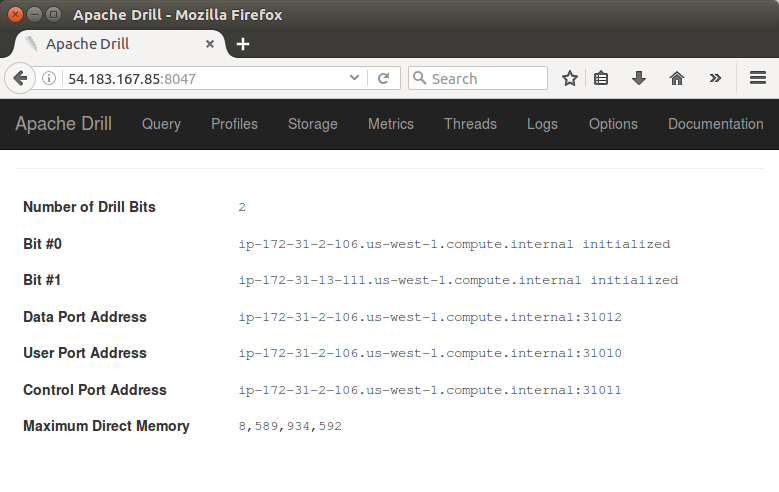
The configurations ((/usr/local/apache-drill-1.8.0/conf/drill-override.conf) for all Drill nodes are the same :
drill.exec: {
cluster-id: "drillbits1",
zk.connect: "54.183.167.85:2181,54.67.74.118:2181"
}
Same configurations for Zookeeper server 1 & 2 (/etc/zookeeper/conf/zoo.cfg):
# the port at which the clients will connect clientPort=2181 # specify all zookeeper servers server.1=54.183.167.85:2888:3888 server.2=54.67.74.118:2888:3888
The server ids for Zookeeper were set in /etc/zookeeper/conf/myid, just a unique numbers: for server #1 : 1, and for server #2 : 2.
Big Data & Drill Tutorials
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization