HashiCorp Vault
If you like to have Vault and Consul containerized, please check out these:
- Docker Compose - Hashicorp's Vault and Consul Part A (install vault, unsealing, static secrets, and policies)
- Docker Compose - Hashicorp's Vault and Consul Part B (EaaS, dynamic secrets, leases, and revocation)
- Docker Compose - Hashicorp's Vault and Consul Part C (Consul)
- Docker & Kubernetes : HashiCorp's Vault and Consul on minikube
- Docker & Kubernetes : HashiCorp's Vault and Consul - Auto-unseal using Transit Secrets Engine
- HashiCorp Vault and Consul on AWS with Terraform
To install Vault, find the appropriate package for the system and download it. Vault is packaged as a zip archive.
After downloading Vault, unzip the package. Vault runs as a single binary named vault. Any other files in the package can be safely removed and Vault will still function.
vault binary is available on the PATH. See this page for instructions on setting the PATH on Linux and Mac.
After installing vault, verify the installation worked by opening a new terminal session and checking that the vault binary is available. By executing vault, we should see help output similar to the following:
$ vault Usage: vault[args] Common commands: read Read data and retrieves secrets write Write data, configuration, and secrets delete Delete secrets and configuration list List data or secrets login Authenticate locally agent Start a Vault agent server Start a Vault server status Print seal and HA status unwrap Unwrap a wrapped secret ...
With Vault installed, the next step is to start a Vault server.
Vault operates as a client/server application. The Vault server is the only piece of the Vault architecture that interacts with the data storage and backends. All operations done via the Vault CLI interact with the server over a TLS connection.
First, we're going to start a Vault dev server. The dev server is a built-in, pre-configured server that is not very secure but useful for playing with Vault locally.
To start the Vault dev server, run:
$ vault server -dev
==> Vault server configuration:
Api Address: http://127.0.0.1:8200
Cgo: disabled
Cluster Address: https://127.0.0.1:8201
Listener 1: tcp (addr: "127.0.0.1:8200", cluster address: "127.0.0.1:8201", max_request_duration: "1m30s", max_request_size: "33554432", tls: "disabled")
Log Level: info
Mlock: supported: false, enabled: false
Storage: inmem
Version: Vault v1.0.3
...
You may need to set the following environment variable:
$ export VAULT_ADDR='http://127.0.0.1:8200'
The unseal key and root token are displayed below in case you want to
seal/unseal the Vault or re-authenticate.
Unseal Key: Ivdz5V/7awjcDme14F3Oln6JRz07vZr65L9DZwkublI=
Root Token: s.lwp09Q4MKWuHLoFu2ohvTTa0
Development mode should NOT be used in production installations!
==> Vault server started! Log data will stream in below:
...
Vault does not fork, so it will continue to run in the foreground. Open another shell or terminal tab to run the remaining commands.
The dev server stores all its data in-memory (but still encrypted), listens on localhost without TLS, and automatically unseals and shows us the unseal key and root access key.
With the dev server running, do the following three things before anything else:
- Launch a new terminal session.
- Copy and run the export VAULT_ADDR ... command from the terminal output. This will configure the Vault client to talk to our dev server.
- Save the unseal key somewhere. Don't worry about how to save this securely. For now, just save it anywhere.
- Copy the generated Root Token value and set is as VAULT_DEV_ROOT_TOKEN_ID environment variable:
$ export VAULT_ADDR='http://127.0.0.1:8200'
$ export VAULT_DEV_ROOT_TOKEN_ID="s.lwp09Q4MKWuHLoFu2ohvTTa0"
Verify the server is running by running the vault status command. This should succeed and exit with exit code 0.
If it ran successfully, the output should look like the following:
$ vault status Key Value --- ----- Seal Type shamir Initialized true Sealed false Total Shares 1 Threshold 1 Version 1.0.3 Cluster Name vault-cluster-0c053b11 Cluster ID 71e7c5d0-04eb-3caa-117e-701a4a2c61b5 HA Enabled false
Now that the dev server is up and running, let's get straight to it and read and write our first secret.
One of the core features of Vault is the ability to read and write arbitrary secrets securely. On this page, we'll do this using the CLI, but there is also a complete HTTP API that can be used to programmatically do anything with Vault.
Secrets written to Vault are encrypted and then written to backend storage. For our dev server, backend storage is in-memory, but in production this would more likely be on disk or in Consul. Vault encrypts the value before it is ever handed to the storage driver. The backend storage mechanism never sees the unencrypted value and doesn't have the means necessary to decrypt it without Vault.
Let's start by writing a secret. This is done very simply with the vault kv command, as shown below:
$ vault kv put secret/hello foo=world Key Value --- ----- created_time 2019-03-18T18:32:38.887747Z deletion_time n/a destroyed false version 1
This writes the pair foo=world to the path secret/hello. We'll cover paths in more detail later, but for now it is important that the path is prefixed with secret/, otherwise this example won't work. The secret/ prefix is where arbitrary secrets can be read and written.
We can even write multiple pieces of data, if we want:
$ vault kv put secret/hello foo=world excited=yes Key Value --- ----- created_time 2019-03-18T18:34:59.445506Z deletion_time n/a destroyed false version 2
vault kv put is a very powerful command. In addition to writing data directly from the command-line, it can read values and key pairs from STDIN as well as files.
The secrets can be gotten with vault get:
$ vault kv get secret/hello ====== Metadata ====== Key Value --- ----- created_time 2019-03-18T18:34:59.445506Z deletion_time n/a destroyed false version 2 ===== Data ===== Key Value --- ----- excited yes foo world
As we can see, the values we wrote are given back to us. Vault gets the data from storage and decrypts it.
The output format is purposefully whitespace separated to make it easy to pipe into a tool like awk.
This contains some extra information. Many secrets engines create leases for secrets that allow time-limited access to other systems, and in those cases lease_id would contain a lease identifier and lease_duration would contain the length of time for which the lease is valid, in seconds.
To print only the value of a given field:
$ vault kv get -field=excited secret/hello yes
Optional JSON output is very useful for scripts. For example below we use the jq tool to extract the value of the excited secret:
$ vault kv get -format=json secret/hello | jq -r .data.data.excited yes
Now that we've learned how to read and write a secret, let's go ahead and delete it. We can do this with vault delete:
$ vault kv delete secret/hello Success! Data deleted (if it existed) at: secret/hello
Vault behaves similarly to a virtual filesystem. The read/write/delete/list operations are forwarded to the corresponding secrets engine, and the secrets engine decides how to react to those operations.
This abstraction is incredibly powerful. It enables Vault to interface directly with physical systems, databases, HSMs, etc. But in addition to these physical systems, Vault can interact with more unique environments like AWS IAM, dynamic SQL user creation, etc. all while using the same read/write interface.
In the previous section, while we're doing read and write arbitrary secrets to Vault, our requests started with secret/. Try the following command which will result an error:
$ vault write foo/bar a=b Error writing data to foo/bar: Error making API request. URL: PUT http://127.0.0.1:8200/v1/foo/bar Code: 404. Errors: * no handler for route 'foo/bar'
Similarly, vault kv put foo/bar a=b will return an error.
The path prefix tells Vault which secrets engine to which it should route traffic. When a request comes to Vault, it matches the initial path part using a longest prefix match and then passes the request to the corresponding secrets engine enabled at that path.
By default, Vault enables a secrets engine called kv at the path secret/. The kv secrets engine reads and writes raw data to the backend storage.
Vault supports many other secrets engines besides kv, and this feature makes Vault flexible and unique. For example, the aws secrets engine generates AWS IAM access keys on demand. The database secrets engine generates on-demand, time-limited database credentials. These are just a few examples of the many available secrets engines.
For simplicity and familiarity, Vault presents these secrets engines similar to a filesystem. A secrets engine is enabled at a path. Vault itself performs prefix routing on incoming requests and routes the request to the correct secrets engine based on the path at which they were enabled.
This section discusses secrets engines and the operations they support. This information is important to both operators who will configure Vault and users who will interact with Vault.
To get started, enable another instance of the kv secrets engine at a different path. Just like a filesystem, Vault can enable a secrets engine at many different paths. Each path is completely isolated and cannot talk to other paths. For example, a kv secrets engine enabled at foo has no ability to communicate with a kv secrets engine enabled at bar.
$ vault secrets enable -path=kv kv Success! Enabled the kv secrets engine at: kv/
The path where the secrets engine is enabled defaults to the name of the secrets engine. Thus, the following commands are actually equivalent:
$ vault secrets enable -path=kv kv $ vault secrets enable kv
To verify our success and get more information about the secrets engine, use the vault secrets list command:
$ vault secrets list Path Type Accessor Description ---- ---- -------- ----------- cubbyhole/ cubbyhole cubbyhole_2a2329af per-token private secret storage identity/ identity identity_56aabb04 identity store kv/ kv kv_e44ff061 n/a secret/ kv kv_ac4edc01 key/value secret storage sys/ system system_4f2059d2 system endpoints used for control, policy and debugging
This shows there are 5 enabled secrets engines on this Vault server. We can see the type of the secrets engine, the corresponding path, and an optional description (or "n/a" if none was given).
Take a few moments to read and write some data to the new kv secrets engine enabled at kv/. Here are a few ideas to get started:
$ vault write kv/my-secret value="s3c(eT" Success! Data written to: kv/my-secret $ vault write kv/hello target=world Success! Data written to: kv/hello $ vault write kv/airplane type=boeing class=787 Success! Data written to: kv/airplane $ vault list kv Keys ---- airplane hello my-secret
When a secrets engine is no longer needed, it can be disabled. When a secrets engine is disabled, all secrets are revoked and the corresponding Vault data and configuration is removed. Any requests to route data to the original path would result in an error, but another secrets engine could now be enabled at that path.
If, for some reason, Vault is unable to delete the data or revoke the leases, the disabling operation will fail. If this happens, the secrets engine will remain enabled and available, but the request will return an error.
$ vault secrets disable kv/ Success! Disabled the secrets engine (if it existed) at: kv/
Note that this command takes a PATH to the secrets engine as an argument, not the TYPE of the secrets engine.
In addition to disabling a secrets engine, it is also possible to "move" a secrets engine to a new path. This is still a disruptive command. All configuration data is retained, but any secrets are revoked, since secrets are closely tied to their engine's paths.
Now that we've experimented with the kv secrets engine, it is time to explore another feature of Vault: dynamic secrets.
Unlike the kv secrets where we had to put data into the store ourselves, dynamic secrets are generated when they are accessed. Dynamic secrets do not exist until they are read, so there is no risk of someone stealing them or another client using the same secrets. Because Vault has built-in revocation mechanisms, dynamic secrets can be revoked immediately after use, minimizing the amount of time the secret existed.
Unlike the kv secrets engine which is enabled by default, the AWS secrets engine must be enabled before use. This step is usually done via a configuration management system.
$ vault secrets enable -path=aws aws Success! Enabled the aws secrets engine at: aws/
The AWS secrets engine is now enabled at aws/. As we covered in the previous sections, different secrets engines allow for different behavior. In this case, the AWS secrets engine generates dynamic, on-demand AWS access credentials.
After enabling the AWS secrets engine, we must configure it to authenticate and communicate with AWS. This requires privileged account credentials. If we are unfamiliar with AWS, use root account keys.
$ vault write aws/config/root \
access_key=AK...5Q \
secret_key=KLj...jb \
region=us-east-1
Success! Data written to: aws/config/root
The next step is to configure a role. A role in Vault is a human-friendly identifier to an action. Think of it as a symlink.
Vault knows how to create an IAM user via the AWS API, but it does not know what permissions, groups, and policies we want to attach to that user. This is where roles come in - roles map our configuration options to those API calls.
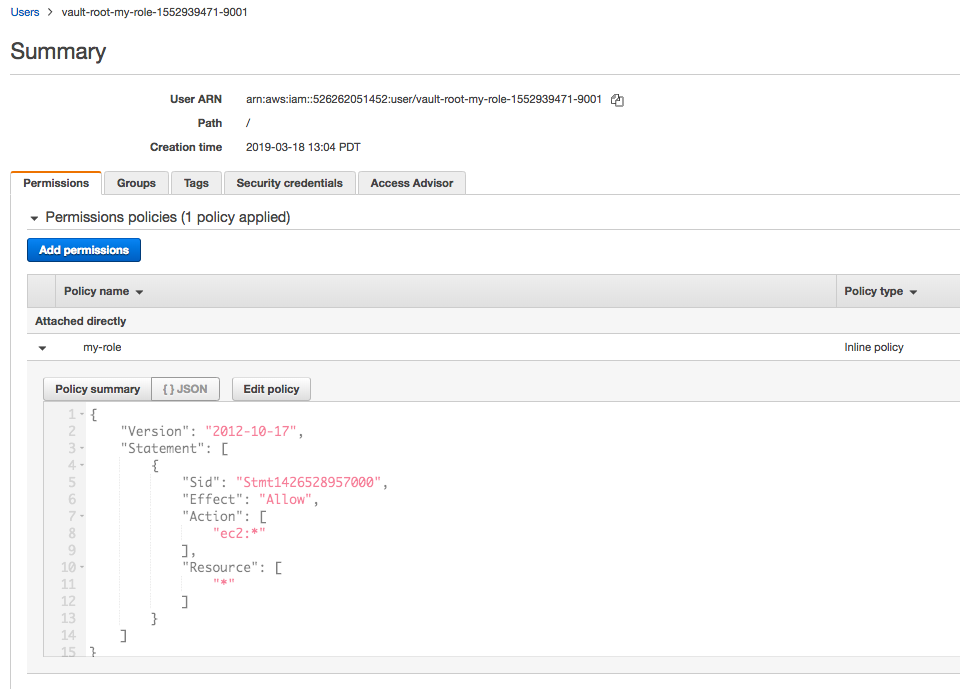
For example, here is an IAM policy that enables all actions on EC2. When Vault generates an access key, it will automatically attach this policy. The generated access key will have full access to EC2 (as dictated by this policy), but not IAM or other AWS services. If not familiar with AWS' IAM policies, that is okay - just use this one for now.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1426528957000",
"Effect": "Allow",
"Action": ["ec2:*"],
"Resource": ["*"]
}
]
}
As mentioned above, we need to map this policy document to a named role. To do that, write to aws/roles/:name where :name is a unique name that describes the role (such as aws/roles/my-role):
$ vault write aws/roles/my-role \
credential_type=iam_user \
policy_document=-<<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1426528957000",
"Effect": "Allow",
"Action": [
"ec2:*"
],
"Resource": [
"*"
]
}
]
}
EOF
Success! Data written to: aws/roles/my-role
Note that we're using a special path here aws/roles/:name to write an IAM policy to Vault. We just told Vault:
When I ask for a credential for "my-role", create it and attach the IAM policy { "Version": "2012..." }.
Let's go into AWS account and check:
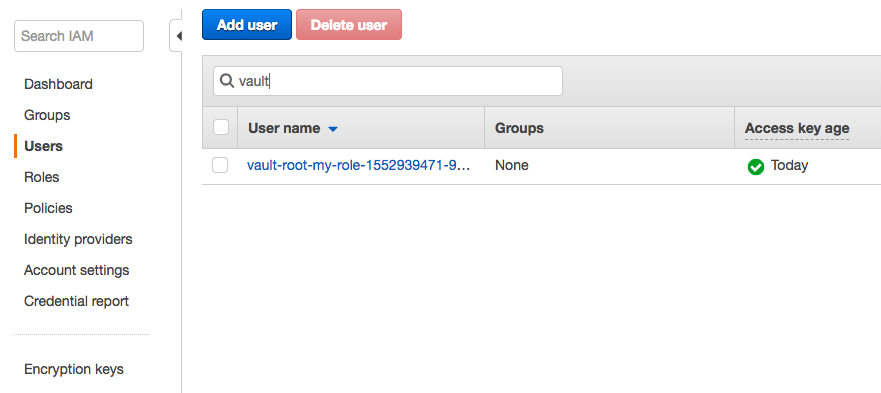
Now that the AWS secrets engine is enabled and configured with a role, we can ask Vault to generate an access key pair for that role by reading from aws/creds/:name where :name corresponds to the name of an existing role:
$ vault read aws/creds/my-role Key Value --- ----- lease_id aws/creds/my-role/bvgZQCEQckDslQbKoMVrOVLv lease_duration 768h lease_renewable true access_key AKIAIY65XACZXRKQ2MLQ secret_key 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 security_token <nil>
Success! The access and secret key can now be used to perform any EC2 operations within AWS. Notice that these keys are new, they are not the keys we entered earlier. If we were to run the command a second time, we would get a new access key pair. Each time we read from aws/creds/:name, Vault will connect to AWS and generate a new IAM user and key pair.
Take careful note of the lease_id field in the output. This value is used for renewal, revocation, and inspection. Copy this lease_id to our clipboard. Note that the lease_id is the full path, not just the UUID at the end.
Vault will automatically revoke this credential after 768 hours (32 days) (see lease_duration in the output), but perhaps we want to revoke it early. Once the secret is revoked, the access keys are no longer valid.
To revoke the secret, use vault revoke with the lease ID that was outputted from vault read when we ran it:
$ vault lease revoke aws/creds/my-role/bvgZQCEQckDslQbKoMVrOVLv All revocation operations queued successfully!
Done! If we login to our AWS account, we will see that no IAM users exist. If we try to use the access keys that were generated, we will find that they no longer work.
With such easy dynamic creation and revocation, we can hopefully begin to see how easy it is to work with dynamic secrets and ensure they only exist for the duration that they are needed.
We've now worked with vault write and vault read for multiple paths: the kv secrets engine with kv/ and dynamic AWS credentials with the AWS secrets engine provider at aws/.
In both cases, the structure and usage of each secrets engines differed, for example the AWS backend has special paths like aws/config.
Now that we know how to use the basics of Vault, it is important to understand how to authenticate to Vault itself.
Up to this point, we have not logged in to Vault. When starting the Vault server in dev mode, it automatically logs us in as the root user with admin permissions. In a non-dev setup, we would have had to authenticate first.
On this page, we'll talk specifically about authentication. Then, later sections, we'll talk about authorization. Authentication is the mechanism of assigning an identity to a Vault user. The access control and permissions associated with an identity are authorization, and will not be covered in this section.
Vault has pluggable auth methods, making it easy to authenticate with Vault using whatever form works best for our organization. In this section we will use the token auth method and the GitHub auth method.
Authentication is the process by which user or machine-supplied information is verified and converted into a Vault token with matching policies attached. The easiest way to think about Vault's authentication is to compare it to a website.
When a user authenticates to a website, they enter their username, password, and maybe 2FA code. That information is verified against external sources (a database most likely), and the website responds with a success or failure. On success, the website also returns a signed cookie that contains a session id which uniquely identifies that user for this session. That cookie and session id are automatically carried by the browser to future requests so the user is authenticated.
Can we imagine how terrible it would be to require a user to enter their login credentials on each page?
Vault behaves very similarly, but it is much more flexible and pluggable than a standard website. Vault supports many different authentication mechanisms, but they all funnel into a single "session token", which we call the "Vault token".
Authentication is simply the process by which a user or machine gets a Vault token.
Token authentication is enabled by default in Vault and cannot be disabled. When we start a dev server with vault server -dev, it prints our root token. The root token is the initial access token to configure Vault. It has root privileges, so it can perform any operation within Vault.
We can create more tokens:
$ vault token create Key Value --- ----- token s.yHEnGe7XnEzQTMCCiWBv02Mg token_accessor 1MHZWUGBRfiKbbtJ7VQX1tVy token_duration ∞ token_renewable false token_policies ["root"] identity_policies [] policies ["root"]
By default, this will create a child token of our current token that inherits all the same policies. The "child" concept here is important: tokens always have a parent, and when that parent token is revoked, children can also be revoked all in one operation. This makes it easy when removing access for a user, to remove access for all sub-tokens that user created as well.
To authenticate with a token:
$ vault login s.yHEnGe7XnEzQTMCCiWBv02Mg is already stored in the token helper. You do NOT need to run "vault login" again. Future Vault requests will automatically use this token. Key Value --- ----- token s.yHEnGe7XnEzQTMCCiWBv02Mg token_accessor 1MHZWUGBRfiKbbtJ7VQX1tVy token_duration ∞ token_renewable false token_policies ["root"] identity_policies [] policies ["root"]
This authenticates with Vault. It will verify our token and let us know what access policies the token is associated with.
After a token is created, we can revoke it:
$ vault token revoke s.yHEnGe7XnEzQTMCCiWBv02Mg Success! Revoked token (if it existed)
In a previous section, we used the vault lease revoke command. This command is only used for revoking leases. For revoking tokens, use vault token revoke.
Log back in with root token:
$ vault login $VAULT_DEV_ROOT_TOKEN_ID Success! You are now authenticated. The token information displayed below is already stored in the token helper. You do NOT need to run "vault login" again. Future Vault requests will automatically use this token. Key Value --- ----- token s.lwp09Q4MKWuHLoFu2ohvTTa0 token_accessor SnvQEKl3wsXiSoFh3PuTeXMS token_duration ∞ token_renewable false token_policies ["root"] identity_policies [] policies ["root"]
Vault supports many auth methods, but they must be enabled before use. Auth methods give us flexibility. Enabling and configuring auth methods are typically performed by a Vault operator or security team. As an example of a human-focused auth method, let's authenticate via GitHub.
First, enable the GitHub auth method:
$ vault auth enable -path=github github Success! Enabled github auth method at: github/
Just like secrets engines, auth methods default to their TYPE as the PATH, so the following commands are equivalent:
$ vault auth enable -path=github github $ vault auth enable github
Unlike secrets engines which are enabled at the root router, auth methods are always prefixed with auth/ in their path. So the GitHub auth method we just enabled is accessible at auth/github. As another example:
$ vault auth enable -path=my-github github Success! Enabled github auth method at: my-github/
This would make the GitHub auth method accessible at auth/my-github. We can use vault path-help to learn more about the paths.
Next, configure the GitHub auth method. Each auth method has different configuration options, in this case, the minimal set of configuration is to map teams to policies.
$ vault write auth/github/config organization=hashicorp Success! Data written to: auth/github/config
With the GitHub auth method enabled, we first have to configure it. For GitHub, we tell it what organization users must be a part of, and map a team to a policy:
$ vault write auth/github/map/teams/my-team value=default,my-policy Success! Data written to: auth/github/map/teams/my-team
The previous command configures Vault to pull authentication data from the "hashicorp" organization on GitHub. The next command tells Vault to map any users who are members of the team "my-team" (in the hashicorp organization) to map to the policies "default" and "my-policy". These policies do not have to exist in the system yet - Vault will just produce a warning when we login.
As a user, we may want to find which auth methods are enabled and available:
$ vault auth list Path Type Accessor Description ---- ---- -------- ----------- github/ github auth_github_3cb0078a n/a my-github/ github auth_github_f5475f28 n/a token/ token auth_token_2e0cad03 token based credentials
The vault auth list command will list all enabled auth methods. To learn more about how to authenticate to a particular auth method via the CLI, use the vault auth help command with the PATH or TYPE of an auth method:
$ vault auth help github
Usage: vault login -method=github [CONFIG K=V...]
The GitHub auth method allows users to authenticate using a GitHub
personal access token. Users can generate a personal access token from the
settings page on their GitHub account.
Authenticate using a GitHub token:
$ vault login -method=github token=abcd1234
Configuration:
mount=
Path where the GitHub credential method is mounted. This is usually
provided via the -path flag in the "vault login" command, but it can be
specified here as well. If specified here, it takes precedence over the
value for -path. The default value is "github".
token=
GitHub personal access token to use for authentication. If not provided,
Vault will prompt for the value.
Similarly, we can ask for help information about any CLI auth method, even if it is not enabled:
$ vault auth help aws $ vault auth help userpass $ vault auth help token
As per the help output, authenticate to GitHub using the vault login command. Enter a GitHub personal access token and Vault will authenticate us.
$ vault login -method=github token=GITHUB_TOKEN Error authenticating: Error making API request. URL: PUT http://127.0.0.1:8200/v1/auth/github/login Code: 400. Errors: * user is not part of required org
For a while, I was stuck at the error "user is not part of required org".
Need to create an org in Github, in my case, "einsteinish-dev", and do the steps again:
$ vault write auth/github/config organization=einsteinish-dev Success! Data written to: auth/github/config $ vault write auth/github/map/teams/my-team value=default,my-policy Success! Data written to: auth/github/map/teams/my-team $ vault login -method=github token=$ vault login -method=github token=748c3b85c04edcc0518f9d9ef75c402ee72801dd Success! You are now authenticated. The token information displayed below is already stored in the token helper. You do NOT need to run "vault login" again. Future Vault requests will automatically use this token. Key Value --- ----- token s.HcGpr7TDmUsi4lyCWrVQuIiw token_accessor 5tmpMDS93SIOR1bWCb23ebS8 token_duration 768h token_renewable true token_policies ["default"] identity_policies [] policies ["default"] token_meta_org einsteinish-dev token_meta_username Einsteinish
Success! As the output indicates, Vault has already saved the resulting token in its token helper, so we do not need to run vault login again. However, this new user we just created does not have many permissions in Vault. To continue, re-authenticate as the root token:
$ vault login $VAULT_DEV_ROOT_TOKEN_ID Success! You are now authenticated. The token information displayed below is already stored in the token helper. You do NOT need to run "vault login" again. Future Vault requests will automatically use this token. Key Value --- ----- token s.lwp09Q4MKWuHLoFu2ohvTTa0 token_accessor SnvQEKl3wsXiSoFh3PuTeXMS token_duration ∞ token_renewable false token_policies ["root"] identity_policies [] policies ["root"] $ vault login s.lwp09Q4MKWuHLoFu2ohvTTa0 Success! You are now authenticated. The token information displayed below is already stored in the token helper. You do NOT need to run "vault login" again. Future Vault requests will automatically use this token. Key Value --- ----- token s.lwp09Q4MKWuHLoFu2ohvTTa0 token_accessor SnvQEKl3wsXiSoFh3PuTeXMS token_duration ∞ token_renewable false token_policies ["root"] identity_policies [] policies ["root"]
We can revoke any logins from an auth method using vault token revoke with the -mode argument. For example:
$ vault token revoke -mode path auth/github Success! Revoked token (if it existed)
Alternatively, if we want to completely disable the GitHub auth method:
$ vault auth disable github Success! Disabled the auth method (if it existed) at: github/
This will also revoke any logins for that auth method.
Terraform
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization