CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM : Hive DB Table and Query
Continued from CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM and QuickStart VMs for CDH 5.3 II - Testing with wordcount, in this chapter, we'll explore Hue and Hive:

Open a browser and go to Hue UI:
We can run one or more MapReduce jobs in the background by using SQL like Hive's HQL.
"Hive is a data warehousing infrastructure based on Hadoop. Hive is designed to enable easy data summarization, ad-hoc querying and analysis of large volumes of data. It provides a simple query language called Hive QL, which is based on SQL and which enables users familiar with SQL to do ad-hoc querying, summarization and data analysis easily. At the same time, Hive QL also allows traditional map/reduce programmers to be able to plug in their custom mappers and reducers to do more sophisticated analysis that may not be supported by the built-in capabilities of the language."
-from Hive Tutorial"Hadoop is a batch processing system and Hadoop jobs tend to have high latency and incur substantial overheads in job submission and scheduling."
"As a result - latency for Hive queries is generally very high (minutes) even when data sets involved are very small (say a few hundred megabytes). As a result it cannot be compared with systems such as Oracle where analyses are conducted on a significantly smaller amount of data but the analyses proceed much more iteratively with the response times between iterations being less than a few minutes. Hive aims to provide acceptable (but not optimal) latency for interactive data browsing, queries over small data sets or test queries. Hive is not designed for online transaction processing and does not offer real-time queries and row level updates. It is best used for batch jobs over large sets of immutable data (like web logs)."
-from Hive TutorialWhile based on SQL, HiveQL does not strictly follow the full SQL-92 standard. HiveQL offers extensions not in SQL, including multitable inserts and create table as select, but only offers basic support for indexes.
Also, HiveQL lacks support for transactions and materialized views, and only limited subquery support. Support for insert, update, and delete with full ACID functionality was made available with release 0.14.
Internally, a compiler translates HiveQL statements into a directed acyclic graph of MapReduce or Tez, or Spark jobs, which are submitted to Hadoop for execution.
- from http://en.wikipedia.org/wiki/Apache_Hive.
We'll create a table with two columns of data: life expectancy and country. The syntax looks like this:
create table expectancy_country (expectancy int, country string) row format delimited fields terminated by ',';
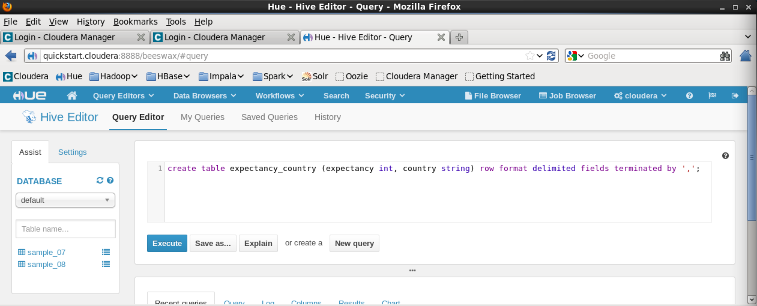
Press Execute button. We can check the log, and can see it's OK:
15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO parse.ParseDriver: Parsing command: create table expectancy_country (expectancy int, country string) row format delimited fields terminated by ',' 15/03/21 12:42:03 INFO parse.ParseDriver: Parse Completed 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO parse.SemanticAnalyzer: Starting Semantic Analysis 15/03/21 12:42:03 INFO parse.SemanticAnalyzer: Creating table expectancy_country position=13 15/03/21 12:42:03 INFO ql.Driver: Semantic Analysis Completed 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 15/03/21 12:42:03 INFO ql.Driver: EXPLAIN output for queryid hive_20150321124242_9ce37a9a-009f-4a14-8a1f-e7a69f6fc2a5 : ABSTRACT SYNTAX TREE: TOK_CREATETABLE TOK_TABNAME expectancy_country TOK_LIKETABLE TOK_TABCOLLIST TOK_TABCOL expectancy TOK_INT TOK_TABCOL country TOK_STRING TOK_TABLEROWFORMAT TOK_SERDEPROPS TOK_TABLEROWFORMATFIELD ',' STAGE DEPENDENCIES: Stage-0 is a root stage [DDL] STAGE PLANS: Stage: Stage-0 Create Table Operator: Create Table columns: expectancy int, country string field delimiter: , input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat serde name: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe name: expectancy_country 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO lockmgr.DummyTxnManager: Creating lock manager of type org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager 15/03/21 12:42:03 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=quickstart.cloudera:2181 sessionTimeout=600000 watcher=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager$DummyWatcher@2658e945 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO ql.Driver: Starting command: create table expectancy_country (expectancy int, country string) row format delimited fields terminated by ',' 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO ql.Driver: OK 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:15/03/21 12:42:03 INFO ZooKeeperHiveLockManager: about to release lock for default 15/03/21 12:42:03 INFO log.PerfLogger: 15/03/21 12:42:03 INFO log.PerfLogger:
Here is our csv data:
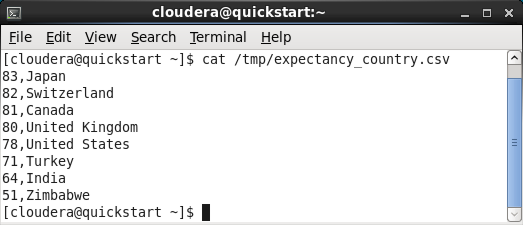
Now, we want to read the data into Hive table:
load data local inpath '/tmp/expectancy_country.csv' overwrite into table expectancy_country;
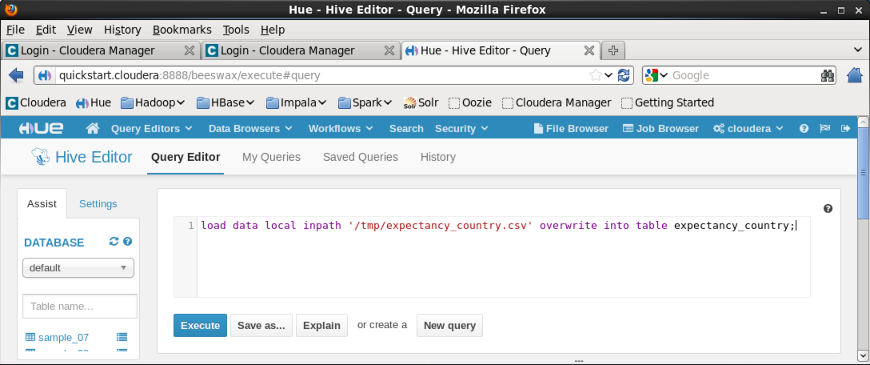
Click Execute, and we get the following log:
We can also check the input file from UI:
15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO parse.ParseDriver: Parsing command: load data local inpath '/tmp/expectancy_country.csv' overwrite into table expectancy_country 15/03/21 14:13:47 INFO parse.ParseDriver: Parse Completed 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1 15/03/21 14:13:47 INFO ql.Driver: Semantic Analysis Completed 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 15/03/21 14:13:47 INFO ql.Driver: EXPLAIN output for queryid hive_20150321141313_ff34b34f-bdfd-4d15-8865-da66bd71aec9 : ABSTRACT SYNTAX TREE: TOK_LOAD '/tmp/expectancy_country.csv' TOK_TAB TOK_TABNAME expectancy_country local overwrite STAGE DEPENDENCIES: Stage-0 is a root stage [COPY] Stage-1 depends on stages: Stage-0 [MOVE] Stage-2 depends on stages: Stage-1 [STATS] STAGE PLANS: Stage: Stage-0 Copy source: file:/tmp/expectancy_country.csv destination: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000 Stage: Stage-1 Move Operator tables: replace: true source: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000 table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: COLUMN_STATS_ACCURATE true bucket_count -1 columns expectancy,country columns.comments � columns.types int:string field.delim , file.inputformat org.apache.hadoop.mapred.TextInputFormat file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat location hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country name default.expectancy_country numFiles 1 numRows 0 rawDataSize 0 serialization.ddl struct expectancy_country { i32 expectancy, string country} serialization.format , serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe totalSize 100 transient_lastDdlTime 1426972319 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe name: default.expectancy_country Stage: Stage-2 Stats-Aggr Operator 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO lockmgr.DummyTxnManager: Creating lock manager of type org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager 15/03/21 14:13:47 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=quickstart.cloudera:2181 sessionTimeout=600000 watcher=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager$DummyWatcher@1d064f96 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO ql.Driver: Starting command: load data local inpath '/tmp/expectancy_country.csv' overwrite into table expectancy_country 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO exec.Task: Copying data from file:/tmp/expectancy_country.csv to hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000 15/03/21 14:13:47 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000 15/03/21 14:13:47 INFO exec.Task: Copying file: file:/tmp/expectancy_country.csv 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO exec.Task: Loading data to table default.expectancy_country from hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000 15/03/21 14:13:47 INFO common.FileUtils: deleting hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/expectancy_country.csv 15/03/21 14:13:47 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes. 15/03/21 14:13:47 INFO common.FileUtils: Moved to trash: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/expectancy_country.csv 15/03/21 14:13:47 INFO metadata.Hive: Replacing src:hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-13-47_408_2193979710479077128-1/-ext-10000/expectancy_country.csv, dest: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/expectancy_country.csv, Status:true 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO ql.Driver: OK 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO exec.StatsTask: Executing stats task 15/03/21 14:13:47 INFO exec.Task: Table default.expectancy_country stats: [numFiles=1, numRows=0, totalSize=100, rawDataSize=0] 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:15/03/21 14:13:47 INFO ZooKeeperHiveLockManager: about to release lock for default/expectancy_country 15/03/21 14:13:47 INFO ZooKeeperHiveLockManager: about to release lock for default 15/03/21 14:13:47 INFO log.PerfLogger: 15/03/21 14:13:47 INFO log.PerfLogger:
Now we can query the data in hdfs:
select * from expectancy_country;

Another query for a list of countries with expectancy > 75:
select * from expectancy_country where expectancy>75;
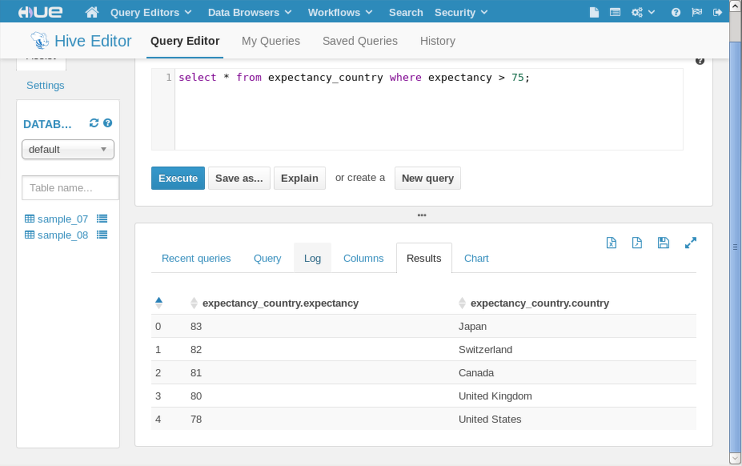
Our Hive query turned into MapReduce job. We can see how MapReduce jobs were done from the log. Our Hive query executed compiled into a MapReduce job executed on the cluster:
15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO parse.ParseDriver: Parsing command: select * from expectancy_country where expectancy > 75 15/03/21 14:36:56 INFO parse.ParseDriver: Parse Completed 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Starting Semantic Analysis 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Completed phase 1 of Semantic Analysis 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Get metadata for source tables 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Get metadata for subqueries 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Get metadata for destination tables 15/03/21 14:36:56 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Completed getting MetaData in Semantic Analysis 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Set stats collection dir : hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1/-ext-10002 15/03/21 14:36:56 INFO ppd.OpProcFactory: Processing for FS(20) 15/03/21 14:36:56 INFO ppd.OpProcFactory: Processing for SEL(19) 15/03/21 14:36:56 INFO ppd.OpProcFactory: Processing for FIL(18) 15/03/21 14:36:56 INFO ppd.OpProcFactory: Pushdown Predicates of FIL For Alias : expectancy_country 15/03/21 14:36:56 INFO ppd.OpProcFactory: (expectancy > 75) 15/03/21 14:36:56 INFO ppd.OpProcFactory: Processing for TS(17) 15/03/21 14:36:56 INFO ppd.OpProcFactory: Pushdown Predicates of TS For Alias : expectancy_country 15/03/21 14:36:56 INFO ppd.OpProcFactory: (expectancy > 75) 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO exec.ListSinkOperator: Initializing Self 22 OP 15/03/21 14:36:56 INFO exec.ListSinkOperator: Operator 22 OP initialized 15/03/21 14:36:56 INFO exec.ListSinkOperator: Initialization Done 22 OP 15/03/21 14:36:56 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:expectancy_country.expectancy, type:int, comment:null), FieldSchema(name:expectancy_country.country, type:string, comment:null)], properties:null) 15/03/21 14:36:56 INFO ql.Driver: EXPLAIN output for queryid hive_20150321143636_a87c2c0b-db60-478c-845e-df0d8aca6810 : ABSTRACT SYNTAX TREE: TOK_QUERY TOK_FROM TOK_TABREF TOK_TABNAME expectancy_country TOK_INSERT TOK_DESTINATION TOK_DIR TOK_TMP_FILE TOK_SELECT TOK_SELEXPR TOK_ALLCOLREF TOK_WHERE > TOK_TABLE_OR_COL expectancy 75 STAGE DEPENDENCIES: Stage-1 is a root stage [MAPRED] Stage-0 is a root stage [FETCH] STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: expectancy_country GatherStats: false Filter Operator isSamplingPred: false predicate: (expectancy > 75) (type: boolean) Select Operator expressions: expectancy (type: int), country (type: string) outputColumnNames: _col0, _col1 File Output Operator compressed: false GlobalTableId: 0 directory: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1/-ext-10001 NumFilesPerFileSink: 1 Stats Publishing Key Prefix: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1/-ext-10001/ table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: columns _col0,_col1 columns.types int:string escape.delim \ hive.serialization.extend.nesting.levels true serialization.format 1 serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe TotalFiles: 1 GatherStats: false MultiFileSpray: false Path -> Alias: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country [expectancy_country] Path -> Partition: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country Partition base file name: expectancy_country input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: COLUMN_STATS_ACCURATE true bucket_count -1 columns expectancy,country columns.comments � columns.types int:string field.delim , file.inputformat org.apache.hadoop.mapred.TextInputFormat file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat location hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country name default.expectancy_country numFiles 1 numRows 0 rawDataSize 0 serialization.ddl struct expectancy_country { i32 expectancy, string country} serialization.format , serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe totalSize 100 transient_lastDdlTime 1426972427 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: COLUMN_STATS_ACCURATE true bucket_count -1 columns expectancy,country columns.comments � columns.types int:string field.delim , file.inputformat org.apache.hadoop.mapred.TextInputFormat file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat location hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country name default.expectancy_country numFiles 1 numRows 0 rawDataSize 0 serialization.ddl struct expectancy_country { i32 expectancy, string country} serialization.format , serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe totalSize 100 transient_lastDdlTime 1426972427 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe name: default.expectancy_country name: default.expectancy_country Truncated Path -> Alias: /expectancy_country [expectancy_country] Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: ListSink 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO physical.MetadataOnlyOptimizer: Looking for table scans where optimization is applicable 15/03/21 14:36:56 INFO physical.MetadataOnlyOptimizer: Found 0 metadata only table scans 15/03/21 14:36:56 INFO parse.SemanticAnalyzer: Completed plan generation 15/03/21 14:36:56 INFO ql.Driver: Semantic Analysis Completed 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO lockmgr.DummyTxnManager: Creating lock manager of type org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager 15/03/21 14:36:56 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=quickstart.cloudera:2181 sessionTimeout=600000 watcher=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager$DummyWatcher@57cc44e7 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO ql.Driver: Starting command: select * from expectancy_country where expectancy > 75 15/03/21 14:36:56 INFO ql.Driver: Total jobs = 1 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO log.PerfLogger:15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:37:23 INFO ql.Driver: MapReduce Jobs Launched: 15/03/21 14:37:23 INFO ql.Driver: Stage-Stage-1: Map: 1 Cumulative CPU: 0.69 sec HDFS Read: 347 HDFS Write: 69 SUCCESS 15/03/21 14:37:23 INFO ql.Driver: Total MapReduce CPU Time Spent: 690 msec 15/03/21 14:37:23 INFO ql.Driver: OK 15/03/21 14:37:23 INFO log.PerfLogger:15/03/21 14:36:56 INFO ql.Driver: Launching Job 1 out of 1 15/03/21 14:36:56 INFO exec.Task: Number of reduce tasks is set to 0 since there's no reduce operator 15/03/21 14:36:56 INFO ql.Context: New scratch dir is hdfs://quickstart.cloudera:8020/tmp/hive-hive/hive_2015-03-21_14-36-56_062_722336335773199805-4 15/03/21 14:36:56 INFO mr.ExecDriver: Using org.apache.hadoop.hive.ql.io.CombineHiveInputFormat 15/03/21 14:36:56 INFO mr.ExecDriver: adding libjars: file:///usr/lib/hive/lib/hive-hbase-handler-0.13.1-cdh5.3.0.jar,file:///usr/lib/hbase/hbase-hadoop-compat.jar,file:///usr/lib/hbase/hbase-client.jar,file:///usr/lib/hbase/hbase-hadoop2-compat.jar,file:///usr/lib/hbase/hbase-protocol.jar,file:///usr/lib/hbase/hbase-server.jar,file:///usr/lib/hbase/lib/htrace-core.jar,file:///usr/lib/hbase/lib/htrace-core-2.04.jar,file:///usr/lib/hbase/hbase-common.jar 15/03/21 14:36:56 INFO exec.Utilities: Processing alias expectancy_country 15/03/21 14:36:56 INFO exec.Utilities: Adding input file hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country 15/03/21 14:36:56 INFO exec.Utilities: Content Summary not cached for hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country 15/03/21 14:36:56 INFO ql.Context: New scratch dir is hdfs://quickstart.cloudera:8020/tmp/hive-hive/hive_2015-03-21_14-36-56_062_722336335773199805-4 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:37:23 INFO log.PerfLogger:15/03/21 14:36:56 INFO exec.Utilities: Serializing MapWork via kryo 15/03/21 14:36:56 INFO log.PerfLogger: 15/03/21 14:36:56 INFO client.RMProxy: Connecting to ResourceManager at quickstart.cloudera/127.0.0.1:8032 15/03/21 14:36:56 INFO client.RMProxy: Connecting to ResourceManager at quickstart.cloudera/127.0.0.1:8032 15/03/21 14:36:56 INFO exec.Utilities: No plan file found: hdfs://quickstart.cloudera:8020/tmp/hive-hive/hive_2015-03-21_14-36-56_062_722336335773199805-4/-mr-10004/fca63f1a-a74c-4c4d-821b-ec569dca189c/reduce.xml 15/03/21 14:36:56 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 15/03/21 14:36:57 INFO log.PerfLogger:15/03/21 14:36:57 INFO io.CombineHiveInputFormat: CombineHiveInputSplit creating pool for hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country; using filter path hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country 15/03/21 14:36:57 INFO input.FileInputFormat: Total input paths to process : 1 15/03/21 14:36:57 INFO input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0 15/03/21 14:36:57 INFO io.CombineHiveInputFormat: number of splits 1 15/03/21 14:36:57 INFO log.PerfLogger: 15/03/21 14:36:57 INFO mapreduce.JobSubmitter: number of splits:1 15/03/21 14:36:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1426957621065_0003 15/03/21 14:36:57 INFO impl.YarnClientImpl: Submitted application application_1426957621065_0003 15/03/21 14:36:57 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1426957621065_0003/ 15/03/21 14:36:57 INFO exec.Task: Starting Job = job_1426957621065_0003, Tracking URL = http://quickstart.cloudera:8088/proxy/application_1426957621065_0003/ 15/03/21 14:36:57 INFO exec.Task: Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1426957621065_0003 15/03/21 14:37:12 INFO exec.Task: Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 15/03/21 14:37:12 WARN mapreduce.Counters: Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead 15/03/21 14:37:12 INFO exec.Task: 2015-03-21 14:37:12,490 Stage-1 map = 0%, reduce = 0% 15/03/21 14:37:21 INFO exec.Task: 2015-03-21 14:37:21,396 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.69 sec 15/03/21 14:37:23 INFO exec.Task: MapReduce Total cumulative CPU time: 690 msec 15/03/21 14:37:23 INFO exec.Task: Ended Job = job_1426957621065_0003 15/03/21 14:37:23 INFO exec.FileSinkOperator: Moving tmp dir: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1/_tmp.-ext-10001 to: hdfs://quickstart.cloudera:8020/user/hive/warehouse/expectancy_country/.hive-staging_hive_2015-03-21_14-36-56_062_722336335773199805-1/-ext-10001 15/03/21 14:37:23 INFO log.PerfLogger:15/03/21 14:37:23 INFO ZooKeeperHiveLockManager: about to release lock for default/expectancy_country 15/03/21 14:37:23 INFO ZooKeeperHiveLockManager: about to release lock for default 15/03/21 14:37:23 INFO log.PerfLogger: 15/03/21 14:37:23 INFO log.PerfLogger:
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization