Apache Hadoop : HBase in Pseudo-distributed mode
In this chapter, continuing from the previous chapter (Apache Hadoop : Creating HBase table with HBase shell and HUE), we're going to create a table with Java. Using Java to interact with HDFS is one of the two basic approaches. The other one? Using HBase shell, which we've done in the previous chapter.
We used the Hadoop installation from Cloudera VM, however, in this chapter, we'll use the basic installation for single node pseudo distribution of Hadoop (Hadoop 2.6 - Installing on Ubuntu 14.04 : Single-Node Cluster).
Let's create a new user and group if we don't have:
ubuntu@laptop $ sudo adduser hduser sudo Adding user `hduser' to group `sudo' ... Adding user hduser to group sudo Done. ubuntu@laptop sudo groupadd hadoop
We can set Hadoop environment variables by appending the following to ~/.bashrc:
hduser@laptop:~$ vi ~/.bashrc #HADOOP VARIABLES START export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" export HADOOP_HOME=$HADOOP_INSTALL #HADOOP VARIABLES END
Now we want to apply all the changes into out current running env:
$ source ~/.bashrc
$ hadoop version Hadoop 2.6.5 hduser@laptop:/usr/local/hadoop$ ls -la drwxr-xr-x 10 hduser hadoop 4096 Nov 10 14:51 . drwxr-xr-x 13 root root 4096 Nov 10 20:26 .. drwxr-xr-x 2 hduser hadoop 4096 Oct 2 16:50 bin drwxr-xr-x 3 hduser hadoop 4096 Oct 2 16:50 etc drwxr-xr-x 2 hduser hadoop 4096 Oct 2 16:50 include drwxr-xr-x 3 hduser hadoop 4096 Oct 2 16:50 lib drwxr-xr-x 2 hduser hadoop 4096 Oct 2 16:50 libexec -rw-r--r-- 1 hduser hadoop 84853 Oct 2 16:50 LICENSE.txt drwxr-xr-x 3 hduser hadoop 4096 Nov 18 23:15 logs -rw-r--r-- 1 hduser hadoop 14978 Oct 2 16:50 NOTICE.txt -rw-r--r-- 1 hduser hadoop 1366 Oct 2 16:50 README.txt drwxr-xr-x 2 hduser hadoop 4096 Nov 18 14:51 sbin drwxr-xr-x 4 hduser hadoop 4096 Oct 2 16:50 share
We can find all the Hadoop configuration files in the location $HADOOP_HOME/etc/hadoop:
hduser@laptop:/usr/local/hadoop/etc/hadoop$ ls *.xml capacity-scheduler.xml hadoop-policy.xml httpfs-site.xml kms-site.xml yarn-site.xml core-site.xml hdfs-site.xml kms-acls.xml mapred-site.xml
The /usr/local/hadoop/etc/hadoop/core-site.xml file contains information such as the port number used for Hadoop instance, memory allocated for file system, memory limit for storing data, and the size of Read/Write buffers.
We can find all the Hadoop configuration files in $HADOOP_HOME/etc/hadoop:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> </property> </configuration>
The /usr/local/hadoop/etc/hadoop/hdfs-site.xml file contains information such as the value of replication data, namenode path, and datanode path of your local file systems, where you want to store the Hadoop infrastructure.
Add the following properties in between the <configuration> and </configuration> tags.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop_store/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop_store/hdfs/datanode</value> </property> </configuration>
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster management yaler, and it is one of the key features in the second-generation Hadoop 2.
/usr/local/hadoop/etc/hadoop/yarn-site.xml is used to configure yarn into Hadoop:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
/usr/local/hadoop/etc/hadoop/mapred-site.xml file is used to specify which MapReduce framework we are using.
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:54311</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
The default port number to access Hadoop is 50070, and let's see Hadoop services on our browser:
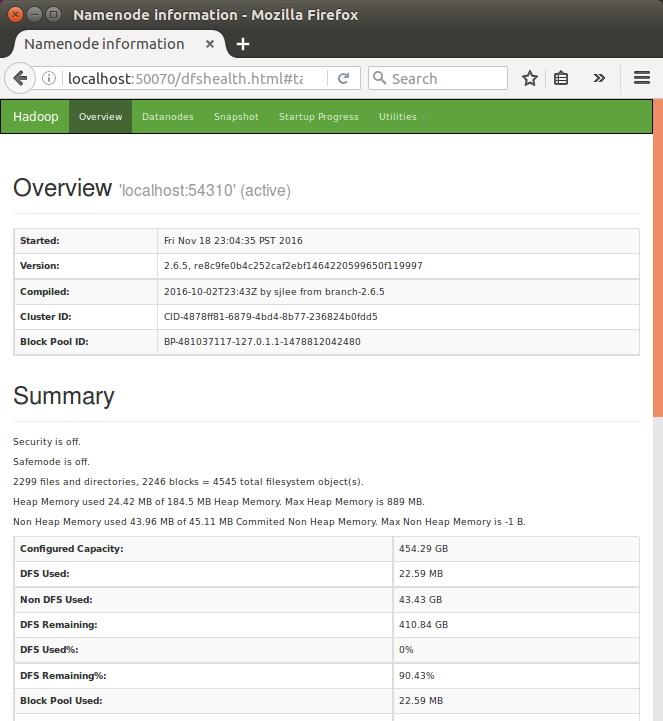
The default port number to access all the applications of cluster is 8088:
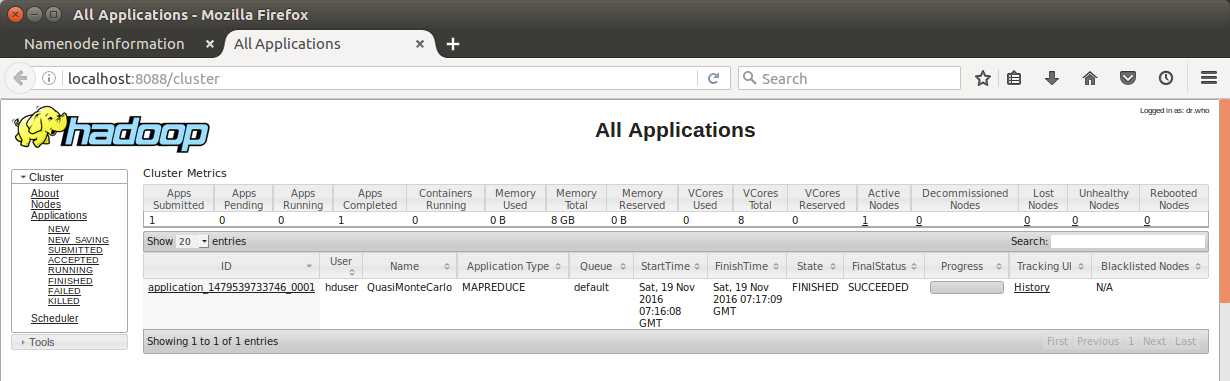
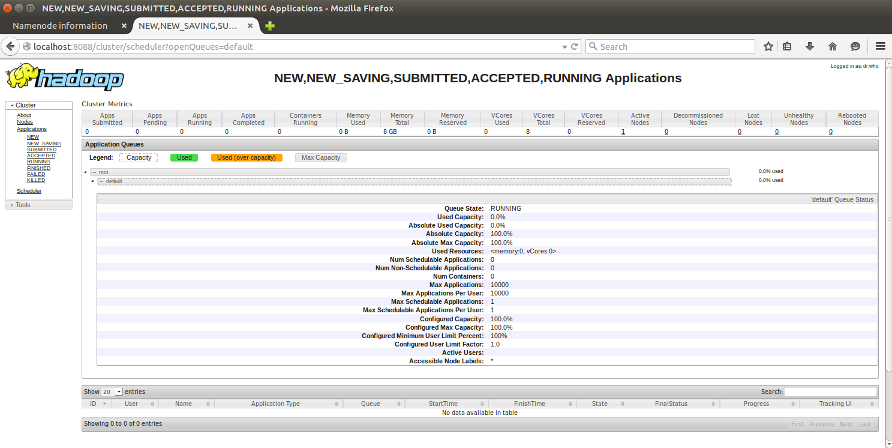
Now that we have made it through setting up Hadoop, we are ready to have created the basis for many other useful applications, two of which are Zookeeper and HBase.
HBase is a column-oriented database management system that runs on top of HDFS. It is well suited for sparse data sets, which are common in many big data system. It is a non-relational, distributed database modeled after Google's BigTable and is written in Java.
One of the necessary components to run HBase is Zookeeper, which serves as a way of synchronizing distributed applications. Zookeeper easily eliminates many of the issues caused by multiple threads accessing data at the same time.
HBase can be installed in any of the three modes:
- Standalone mode
- Pseudo Distributed mode
- Fully Distributed mode
But we're going to install HBase in Pseudo Distributed mode in this tutorial.
Pseudo-distributed mode means that HBase still runs completely on a single host, but each HBase daemon (HMaster, HRegionServer, and Zookeeper) runs as a separate process.
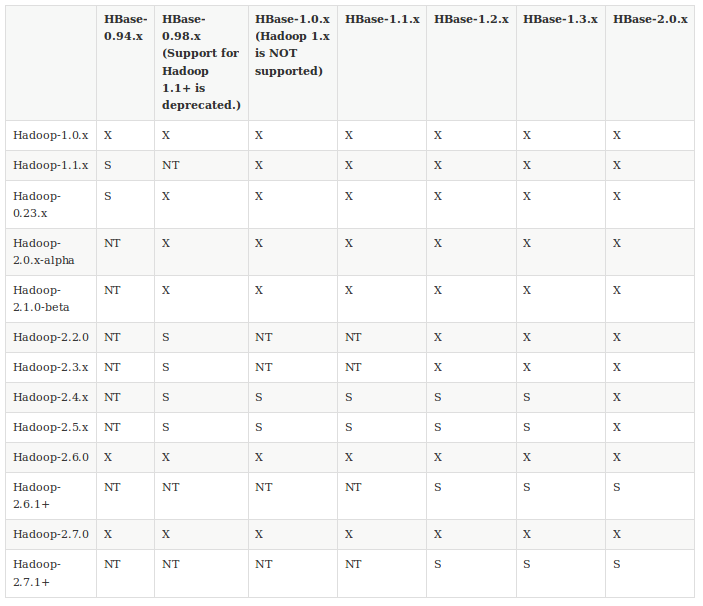
Selecting a Hadoop version is critical for your HBase deployment.
Below table shows some information about what versions of Hadoop are supported by various HBase versions.(Apache HBase Configuration)
Hadoop version support matrix

Download the latest stable version of HBase form (http://www.apache.org/dyn/closer.cgi/hbase/):
hduser@laptop:~$ wget http://www-us.apache.org/dist/hbase/stable/hbase-1.2.4-bin.tar.gz hduser@laptop:~$ tar xvzf hbase-1.2.4-bin.tar.gz hduser@laptop:~$ sudo mv hbase-1.2.4 /usr/local/hbase/
export HBASE_HOME=/usr/local/hbase export PATH=$PATH:$HBASE_HOME/bin
We need to run the file:
hduser@laptop:~$ source ~/.bashrc
Set the Java Home for HBase and open /usr/local/hbase/conf/hbase-env.sh file:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers
export HBASE_MANAGES_ZK=true
A distributed Apache HBase installation depends on a running ZooKeeper cluster. All participating nodes and clients need to be able to access the running ZooKeeper ensemble.
Apache HBase by default manages a ZooKeeper "cluster" for us. It will start and stop the ZooKeeper ensemble as part of the HBase start/stop process. We can also manage the ZooKeeper ensemble independent of HBase and just point HBase at the cluster it should use.
To toggle HBase management of ZooKeeper, we can use the HBASE_MANAGES_ZK variable in conf/hbase-env.sh. This variable, which defaults to true, tells HBase whether to start/stop the ZooKeeper ensemble servers as part of HBase start/stop, which is the setup in this tutorial.
Note that we need to edit conf/hbase-site.xml and set hbase.zookeeper.property.clientPort and hbase.zookeeper.quorum.
/usr/local/hbase/conf/hbase-site.xml is the main HBase configuration file. We only need to specify the directory on the local filesystem where HBase and ZooKeeper write data.
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:54310/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hduser/zookeeper</value>
</property>
</configuration>
We opted to have HBase manage a ZooKeeper quorum which is bound to port 2222 (the default is 2181). Note that we set HBASE_MANAGE_ZK to true in conf/hbase-env.sh.
We should also set hbase.zookeeper.property.dataDir to other than the default as the default has ZooKeeper persist data under /tmp which is often cleared on system restart. In our configuration above, we have ZooKeeper persist to /user/local/zookeeper.
With the setup in the preceeding sections, the HBase installation and configuration part is successfully complete. We can start HBase by using start-hbase.sh script provided in the bin folder of HBase.
Before starting HBase, we need to make sure Hadoop is running:
hduser@laptop:/usr/local/hbase/bin$ jps 17874 DataNode 18048 SecondaryNameNode 19889 Jps 18182 ResourceManager 18488 NodeManager 17733 NameNode
We can start HBase by using start-hbase.sh script provided in the bin folder of HBase:
hduser@laptop:/usr/local/hbase/bin$ start-hbase.sh localhost: starting zookeeper, logging to /usr/local/hbase/bin/../logs/hbase-hduser-zookeeper-laptop.out starting master, logging to /usr/local/hbase/logs/hbase-hduser-master-laptop.out starting regionserver, logging to /usr/local/hbase/logs/hbase-hduser-1-regionserver-laptop.out
If our system is configured correctly, the jps command should show the HMaster and HRegionServer processes running:
hduser@laptop:/usr/local/hbase/bin$ jps 19296 DataNode 19185 NameNode 19937 NodeManager 32034 HQuorumPeer 32178 HRegionServer 19494 SecondaryNameNode 32091 HMaster 32606 Jps 19823 ResourceManager
We can also see HQuorumPeer which is HBase's version of ZooKeeper's QuorumPeer is also running. Since we let HBase manage ZooKeeper, HQuorumPeer is used to start up QuorumPeer instances. By doing things in here rather than directly calling to ZooKeeper, we have more control over the process.
We can use the HBase Shell to create a table, populate it with data, scan and get values from it as in Apache Hadoop : Creating HBase table with HBase shell and HUE.
hduser@laptop:/usr/local/hbase/bin$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.4, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016 hbase(main):001:0>
Utilities->Browse the file system:
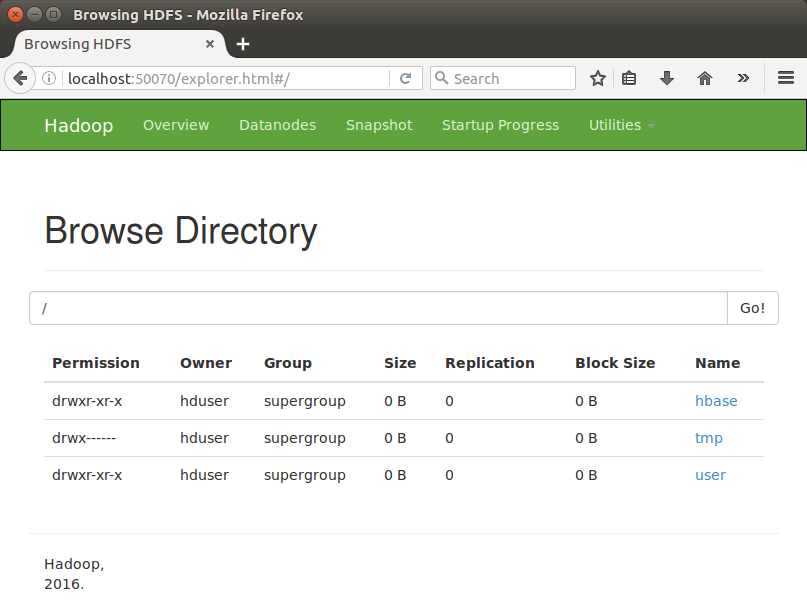
Click "hbase":
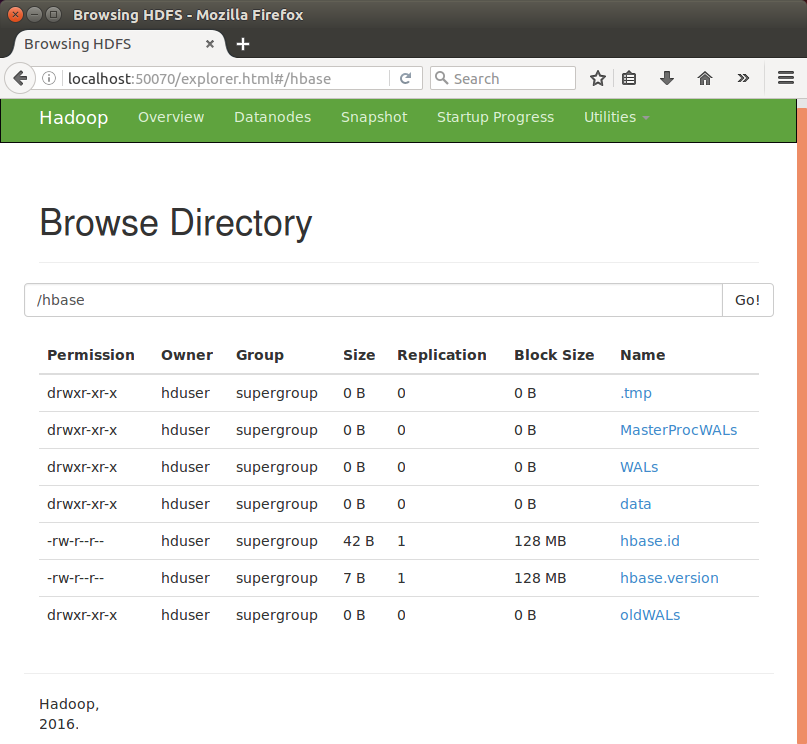
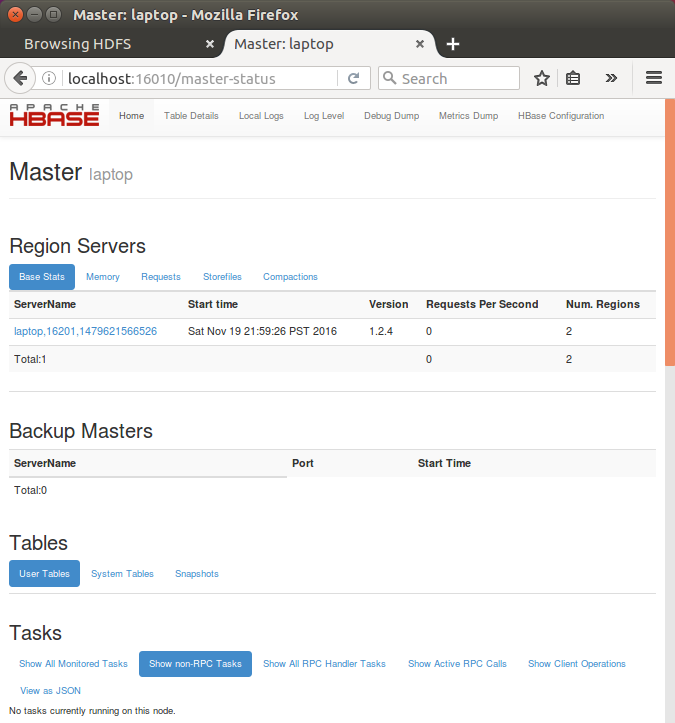
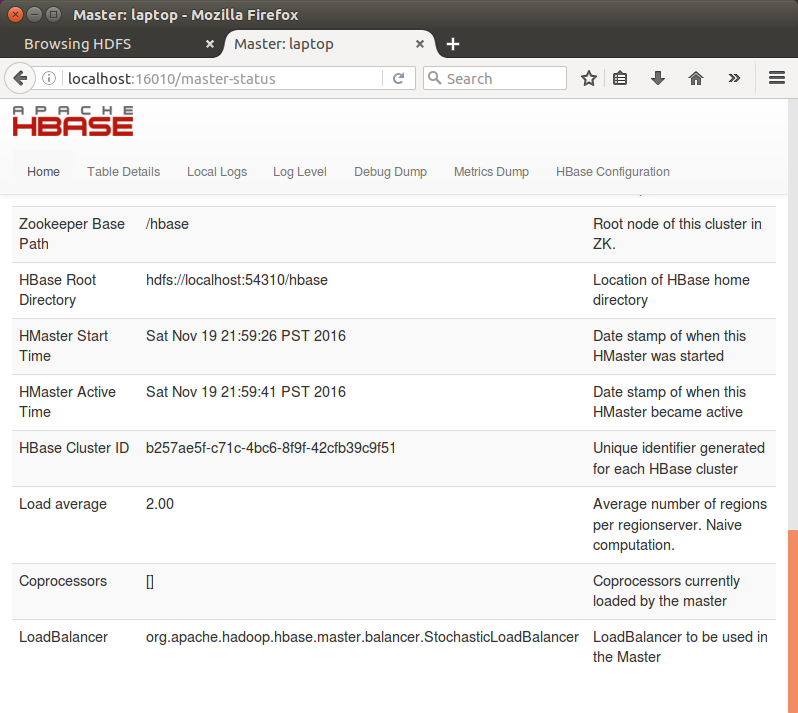
To access the web interface of HBase, type the following url in the browser:
http://localhost:16010
This interface lists our currently running Region servers, backup masters and HBase tables:
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization