Apache Drill - Query File System, JSON, and Parquet
We installed Drill and Zookeeper in the previous tutorial : Apache Drill with ZooKeeper - Install on Ubuntu 16.04, and we learned how to use Drill in distributed system with Zookeeper.
Now, in this tutorial, we'll see how we can use Drill.
Drill has several utilities as we can see them listed under the bin directory:
Let's start the Drill shell. The Drill shell is a pure-Java console-based utility for connecting to relational databases and executing SQL commands. Drill follows the SQL:2011 standard.
Before we start Drill, let's navigate to the Drill installation directory (/usr/local/apache-drill-1.8.0) and issue the following drill-embedded command which connecting to a local embedded instance (note that we don't need Zookeeper in this case):
root@laptop:/usr/local/apache-drill-1.8.0# bin/drill-embedded ... INFO: Initiating Jersey application, version Jersey: 2.8 2014-04-29 01:25:26... apache drill 1.8.0 ... 0: jdbc:drill:zk=local>
Embedded mode requires less configuration & it is preferred for testing purpose.
As we can see from the message, we got 0: jdbc:drill:zk=local> prompt which suggests the drill-embedded command uses a jdbc connection string and identifies the local node as the ZooKeeper node.
Here is the description about the prompt:
- 0 is the number of connections to Drill, which can be only one in embedded node.
- jdbc is the connection type.
- zk=local zk=local means the local node substitutes for the ZooKeeper node. In other words, Drill in embedded mode does not require installation of ZooKeeper.
Note that drillbit (Drill daemon) starts automatically in embedded mode.
Now the Drill shell is running:
$ netstat -nlpt|grep 8047 tcp6 0 0 :::8047 :::* LISTEN -
To exit the Drill shell, issue !quit command:<./p>
0: jdbc:drill:zk=local> !quit Closing: org.apache.drill.jdbc.impl.DrillConnectionImpl root@laptop:/usr/local/apache-drill-1.8.0/bin#
A sample JSON file, employee.json, contains employee data. To view the data in the employee.json file, submit the following SQL query to Drill, using the cp (classpath) storage plugin configuration to point to JAR files in the Drill classpath such as employee.json that we can query.
The employee.json file is packaged in the Foodmart data JAR in Drill's classpath, /jars/3rdparty/foodmart-data-json.0.4.jar, and the snippet of the file looks like this:
{"employee_id":1,"full_name":"Sheri Nowmer","first_name":"Sheri","last_name":"Nowmer","position_id":1,"position_title":"President","store_id":0,"department_id":1,"birth_date":"1961-08-26","hire_date":"1994-12-01 00:00:00.0","end_date":null,"salary":80000.0000,"supervisor_id":0,"education_level":"Graduate Degree","marital_status":"S","gender":"F","management_role":"Senior Management"}
{"employee_id":2,"full_name":"Derrick Whelply","first_name":"Derrick","last_name":"Whelply","position_id":2,"position_title":"VP Country Manager","store_id":0,"department_id":1,"birth_date":"1915-07-03","hire_date":"1994-12-01 00:00:00.0","end_date":null,"salary":40000.0000,"supervisor_id":1,"education_level":"Graduate Degree","marital_status":"M","gender":"M","management_role":"Senior Management"}
...
As discussed, to query a file in a JAR file in the Drill classpath, we need to use the cp (classpath) storage plugin configuration.
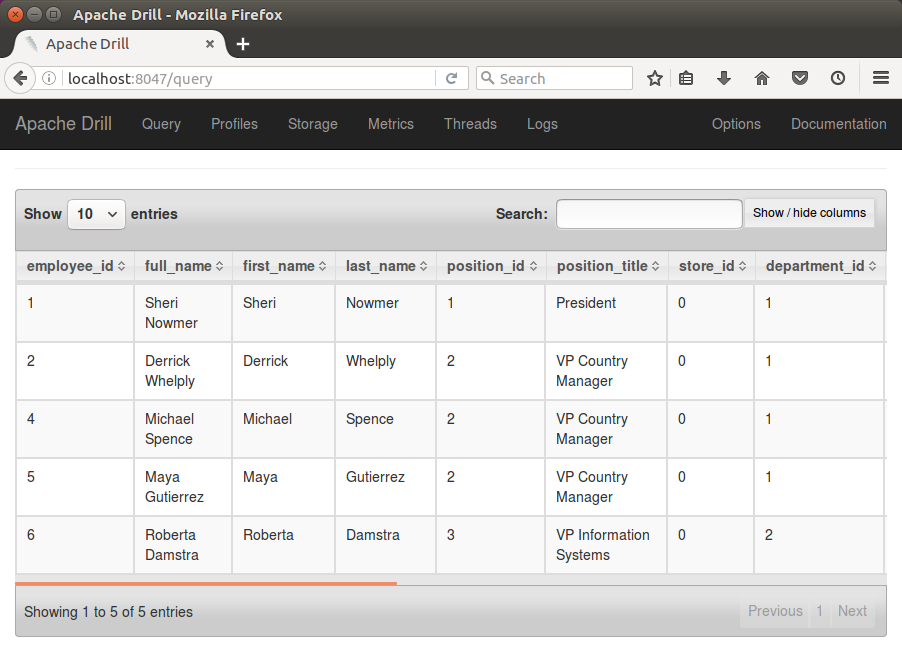
Let's select 5 rows of data from the employee.json file installed with Drill:
0: jdbc:drill:zk=local> SELECT * FROM cp.`employee.json` LIMIT 5;
The query returns the following results:
+--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+ | employee_id | full_name | first_name | last_name | position_id | position_title | store_id | department_id | birth_date | hire_date | salary | supervisor_id | education_level | marital_status | gender | management_role | +--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+ | 1 | Sheri Nowmer | Sheri | Nowmer | 1 | President | 0 | 1 | 1961-08-26 | 1994-12-01 00:00:00.0 | 80000.0 | 0 | Graduate Degree | S | F | Senior Management | | 2 | Derrick Whelply | Derrick | Whelply | 2 | VP Country Manager | 0 | 1 | 1915-07-03 | 1994-12-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | M | M | Senior Management | | 4 | Michael Spence | Michael | Spence | 2 | VP Country Manager | 0 | 1 | 1969-06-20 | 1998-01-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | S | M | Senior Management | | 5 | Maya Gutierrez | Maya | Gutierrez | 2 | VP Country Manager | 0 | 1 | 1951-05-10 | 1998-01-01 00:00:00.0 | 35000.0 | 1 | Bachelors Degree | M | F | Senior Management | | 6 | Roberta Damstra | Roberta | Damstra | 3 | VP Information Systems | 0 | 2 | 1942-10-08 | 1994-12-01 00:00:00.0 | 25000.0 | 1 | Bachelors Degree | M | F | Senior Management | +--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+ 5 rows selected (14.072 seconds)
On the Web console, it looks like this:
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
The Drill installation includes a sample-data directory with Parquet files that we can query. Use SQL to query the region.parquet and nation.parquet files in the sample-data directory.
To view the data in the region.parquet file, use the actual path to our Drill installation to construct this query:
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/usr/local/apache-drill-1.8.0/sample-data/region.parquet`;
The query returns the following results:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. +--------------+--------------+-----------------------+ | R_REGIONKEY | R_NAME | R_COMMENT | +--------------+--------------+-----------------------+ | 0 | AFRICA | lar deposits. blithe | | 1 | AMERICA | hs use ironic, even | | 2 | ASIA | ges. thinly even pin | | 3 | EUROPE | ly final courts cajo | | 4 | MIDDLE EAST | uickly special accou | +--------------+--------------+-----------------------+ 5 rows selected (1.452 seconds) 0: jdbc:drill:zk=local>
To view the data in the nation.parquet file, issue the query appropriate for your operating system:
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/usr/local/apache-drill-1.8.0/sample-data/nation.parquet`;
The query returns the following results:
+--------------+-----------------+--------------+-----------------------+ | N_NATIONKEY | N_NAME | N_REGIONKEY | N_COMMENT | +--------------+-----------------+--------------+-----------------------+ | 0 | ALGERIA | 0 | haggle. carefully f | | 1 | ARGENTINA | 1 | al foxes promise sly | | 2 | BRAZIL | 1 | y alongside of the p | | 3 | CANADA | 1 | eas hang ironic, sil | | 4 | EGYPT | 4 | y above the carefull | | 5 | ETHIOPIA | 0 | ven packages wake qu | | 6 | FRANCE | 3 | refully final reques | | 7 | GERMANY | 3 | l platelets. regular | | 8 | INDIA | 2 | ss excuses cajole sl | | 9 | INDONESIA | 2 | slyly express asymp | | 10 | IRAN | 4 | efully alongside of | | 11 | IRAQ | 4 | nic deposits boost a | | 12 | JAPAN | 2 | ously. final, expres | | 13 | JORDAN | 4 | ic deposits are blit | | 14 | KENYA | 0 | pending excuses hag | | 15 | MOROCCO | 0 | rns. blithely bold c | | 16 | MOZAMBIQUE | 0 | s. ironic, unusual a | | 17 | PERU | 1 | platelets. blithely | | 18 | CHINA | 2 | c dependencies. furi | | 19 | ROMANIA | 3 | ular asymptotes are | | 20 | SAUDI ARABIA | 4 | ts. silent requests | | 21 | VIETNAM | 2 | hely enticingly expr | | 22 | RUSSIA | 3 | requests against th | | 23 | UNITED KINGDOM | 3 | eans boost carefully | | 24 | UNITED STATES | 1 | y final packages. sl | +--------------+-----------------+--------------+-----------------------+ 25 rows selected (0.453 seconds)
The Drill installation registers the cp, dfs, hbase, hive, and mongo default storage plugin configurations. In the above querying samples, we used cp and dfs storage plugin.
We can use Drill Web Console to view and reconfigure a storage plugin:
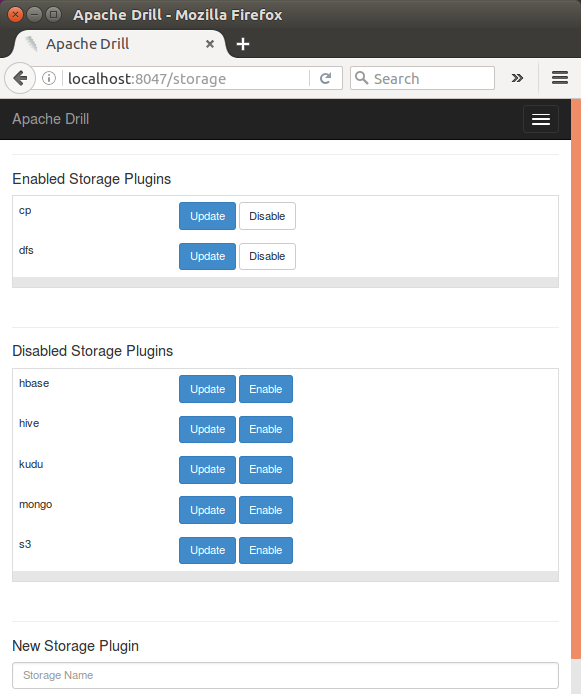
Here is the list of default storage plugin configurations:
- cp
Points to JAR files in the Drill classpath, as we did with employee.json earlier. - dfs
Points to the local file system (see the previous example), but we can configure this storage plugin to point to any distributed file system, such as a Hadoop or S3 file system. - hbase
Provides a connection to HBase. - hive
Integrates Drill with the Hive metadata abstraction of files, HBase, and libraries to read data and operate on SerDes and UDFs. - mongo
Provides a connection to MongoDB data.
Big Data & Drill Tutorials
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization